SSH & JDK部署
互联互通
在哥们(hhh)的帮助下,搞到四台阿里云服务器,不过挺寒碜的配置:
| 编号 | IP | 用户名 | 密码 | 系统配置 | 备注 |
|---|---|---|---|---|---|
| 1 | 8.219.xx0.46 | root | —- | Ubuntu 22.04 | 2vCPU/4GiB | 主节点 |
| 2 | 4x.236.2x.161 | root | —- | Ubuntu 22.04 | 2vCPU/1GiB | 从节点 |
| 3 | 4x.236.15x.1x2 | root | —- | Ubuntu 22.04 | 2vCPU/2GiB | 从节点 |
| 4 | 47.2x6.x15.x57 | root | —- | Ubuntu 22.04 | 2vCPU/1GiB | 客户端 |
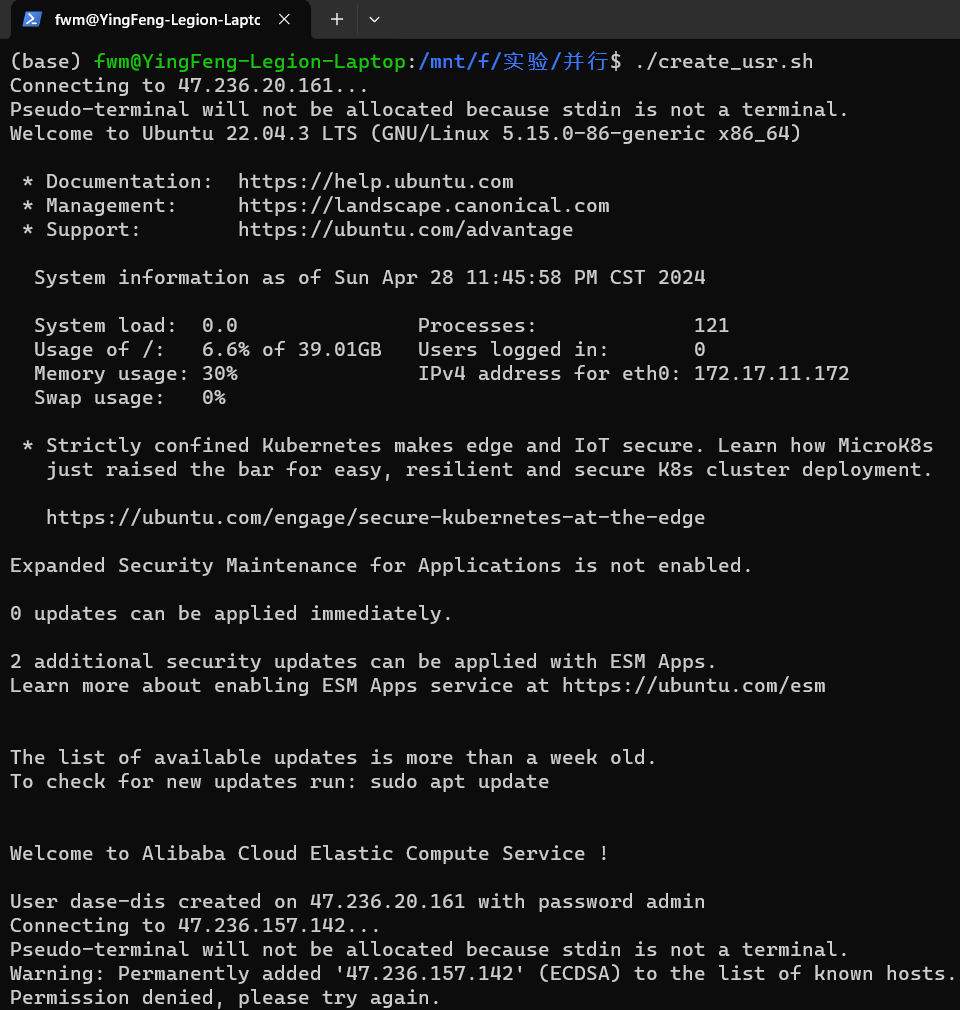
写了一个shell脚本,在四台服务器上创建用户dase-dis(注意确保四台服务器的用户名和密码一致才可以使用):
先sudo apt install sshpass,在Linux下执行脚本:
1 |
|
执行结果:
实现四台服务器之间ssh免密登录
安装openssh
在四台服务器上执行
sudo apt-get install openssh-server安装openssh
更改主机名
在1号机(主节点,在文章开头编号1)执行:
sudo hostnamectl set-hostname ecnu01更改主机名
在2号机(从节点,在文章开头编号2)执行:
sudo hostnamectl set-hostname ecnu02
…以此类推
sudo hostnamectl set-hostname ecnu03sudo hostnamectl set-hostname ecnu04
四台服务器都执行完毕后,断开ssh重新连接,观察到主机名字已经成功更改

更改hosts
原理:
Hosts文件是本地计算机上的文本文件,用于将主机名与IP地址关联起来,绕过DNS解析。Linux hosts文件的格式通常是:
IP地址 主机名 [别名...]在
/etc/hosts路径下,每行代表一个主机名到IP地址的映射。例如:
2
3
::1 localhost
192.168.1.2 example.com其中,127.0.0.1 和 ::1 映射到 localhost,192.168.1.2 映射到 example.com。hosts 文件允许手动指定主机名与 IP 地址的对应关系,用于特定网络配置和测试。
开始修改:
在四台机上执行以下操作:
sudo vim /etc/hosts
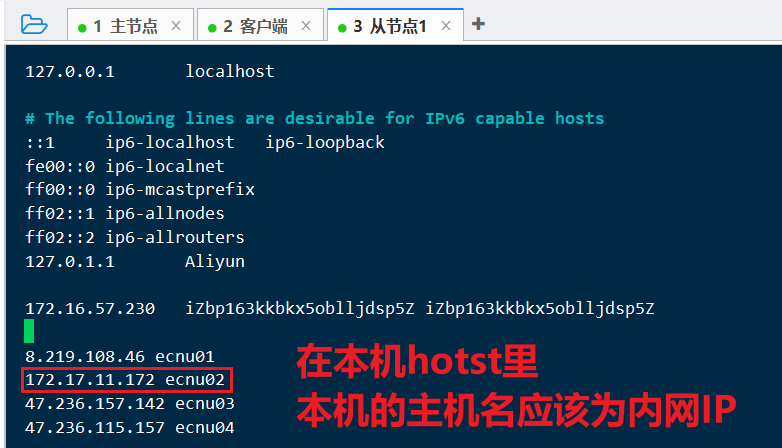
在hosts文件后追加(ip需要改成自己的哇):
1 | # IP地址 主机名 |
!!!!!!!注意!!!!!!!!!
!!!!!!!注意!!!!!!!!!
!!!!!!!注意!!!!!!!!!
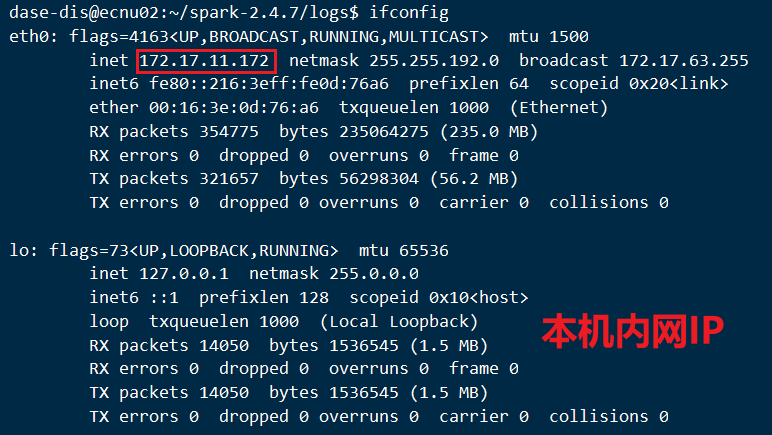
在云服务器配置时, 本机使用内网IP, 其余为公网IP
查看内网IP:
hosts数值示例:
拷贝ssh公钥
在所有机器依次执行下面命令:
作用是将除主机外的三台机的ssh公钥拷贝到主中,实现其余三台机器到主机的ssh免密登录
ssh-keygen -t rsa生成ssh密钥ssh dase-dis@ecnu01 'mkdir -p ~/.ssh && cat >> ~/.ssh/authorized_keys' < ~/.ssh/id_rsa.pub发送公钥到主机sudo service ssh restart && chmod 700 ~/.ssh && chmod 600 ~/.ssh/authorized_keys重启本机ssh服务+解决ssh文件夹的权限问题
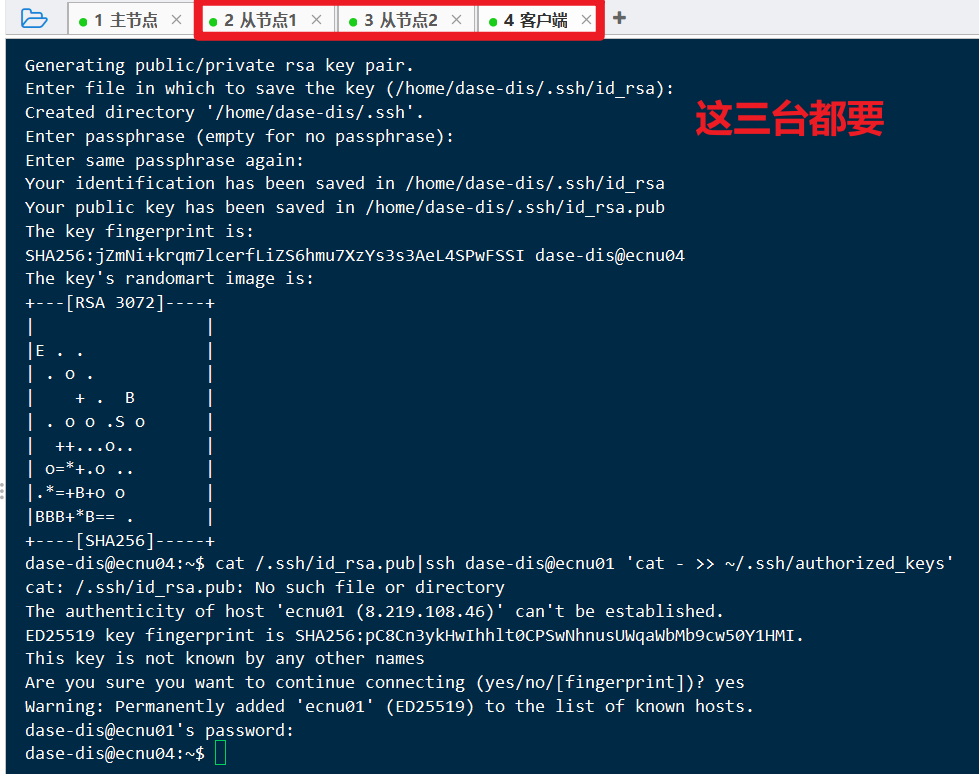
主机执行:
作用是将主机的ssh认证拷贝到其余三台机中,实现其余三台机器之间的ssh免密登录
scp ~/.ssh/authorized_keys dase-dis@ecnu02:/home/dase-dis/.ssh/authorized_keysscp ~/.ssh/authorized_keys dase-dis@ecnu03:/home/dase-dis/.ssh/authorized_keysscp ~/.ssh/authorized_keys dase-dis@ecnu04:/home/dase-dis/.ssh/authorized_keys
上面的三条命令等价于命令:for host in ecnu02 ecnu03 ecnu04; do scp ~/.ssh/authorized_keys dase-dis@$host:/home/dase-dis/.ssh/; done
然后主机执行:
sudo service ssh restart && chmod 700 ~/.ssh && chmod 600 ~/.ssh/authorized_keys
运行结果:
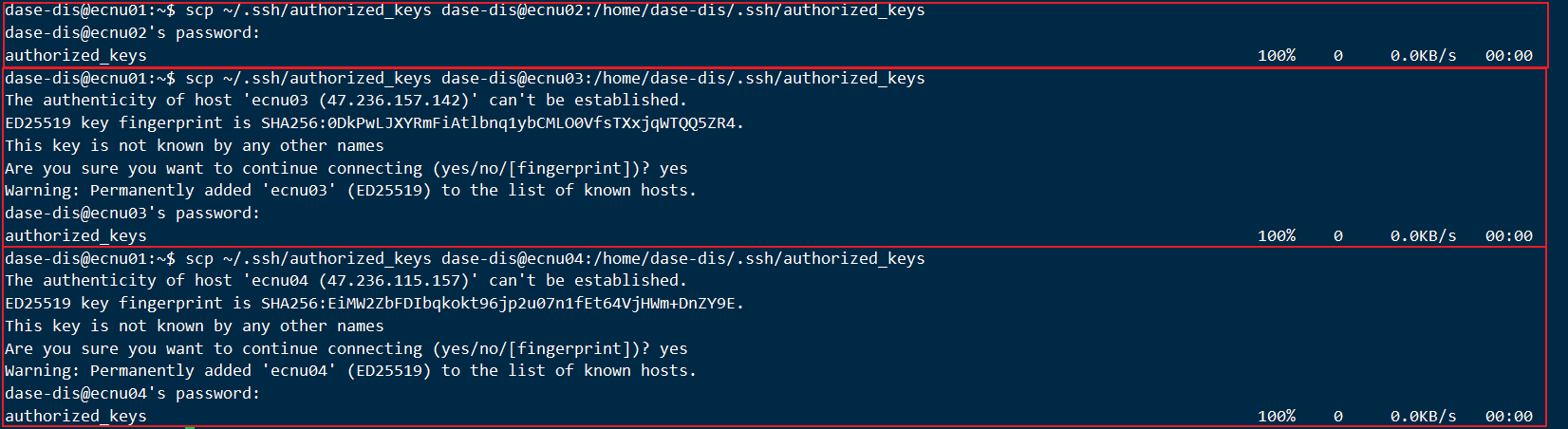
验证:
互相ssh过去看看要不要输入密码
1 | ssh dase-dis@ecnu01 |
关闭防火墙
如果你是本地虚拟机:
systemctl stop firewalld.servicesystemctl disable firewalld.service
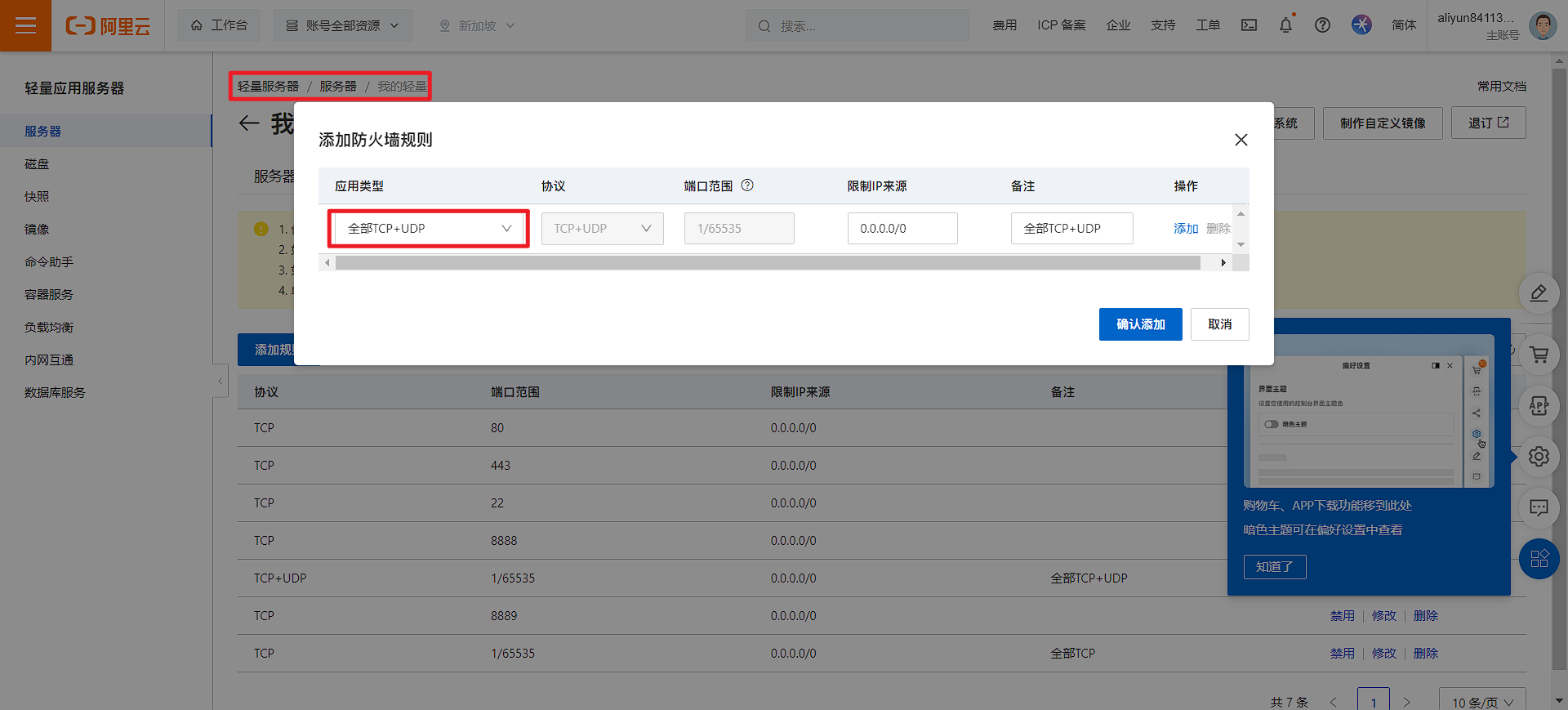
如果你是云服务器:
请确保你知道自己在干什么, 关闭防火墙(开放所有端口)可能导致服务器被入侵
配置Java环境
在四台机器上配置:
可能你需要在上面oracle网站登陆后上手动找到下载地址,然后使用wget下载
下载:
wget https://download.oracle.com/otn/java/jdk/8u202-b08/1961070e4c9b4e26a04e7f5a083f551e/jdk-8u202-linux-x64.tar.gz解压:
tar -zxvf jdk-8u202-linux-x64.tar.gz环境变量配置:
sudo vi /etc/profile添加以下内容:
1 | 路径自己配自己的 |
刷新:
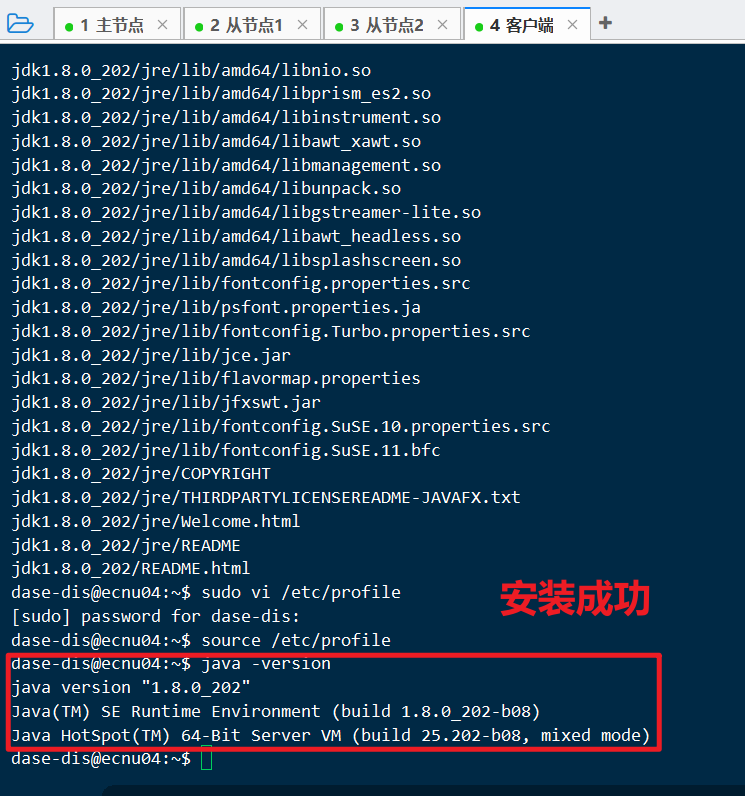
source /etc/profile验证:
java -version
Hadoop 2.x部署
下载
地址:https://archive.apache.org/dist/hadoop/common/hadoop-2.10.1/hadoop-2.10.1.tar.gz
在主节点上执行:
下载:
wget https://archive.apache.org/dist/hadoop/common/hadoop-2.10.1/hadoop-2.10.1.tar.gz解压:
tar -zxvf hadoop-2.10.1.tar.gz
进入文件夹:
cd ~/hadoop-2.10.1/查看下载软件的版本:
./bin/hadoop version
修改配置
修改slaves
在主节点上执行:
- 修改 slaves 文件:
vim ~/hadoop-2.10.1/etc/hadoop/slaves
修改为:
1 | ecnu02 |
修改core-site
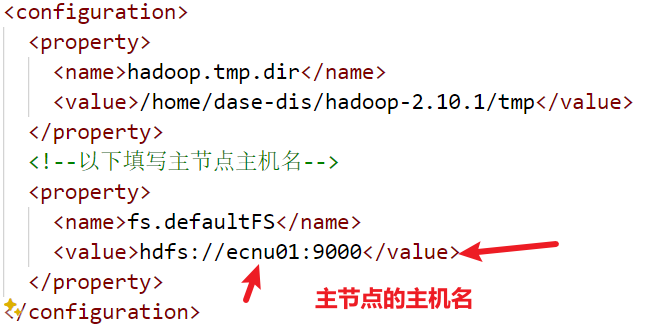
- 修改 core-site.xml:
vim ~/hadoop-2.10.1/etc/hadoop/core-site.xml
1 |
|
修改hdfs-site
- 修改 hdfs-site.xml:
vim ~/hadoop-2.10.1/etc/hadoop/hdfs-site.xml
1 |
|
修改hadoop-env
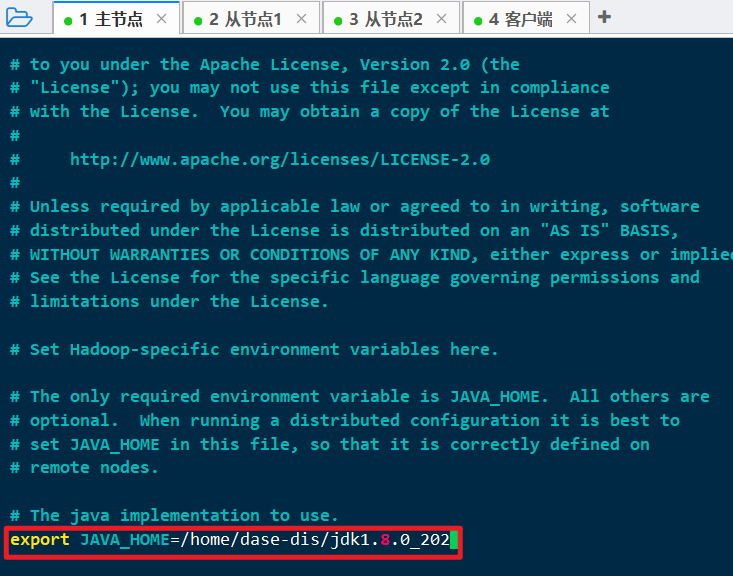
修改 hadoop-env.sh:
vim ~/hadoop-2.10.1/etc/hadoop/hadoop-env.sh将
JAVA_HOME改为:
1 | export JAVA_HOME=/home/dase-dis/jdk1.8.0_202 |
拷贝安装包
好了好了,终于改完了,接下来将改好的这份hadoop拷贝到其余三台机:
拷贝到从节点1:
scp -r /home/dase-dis/hadoop-2.10.1 dase-dis@ecnu02:/home/dase-dis/拷贝到从节点2:
scp -r /home/dase-dis/hadoop-2.10.1 dase-dis@ecnu03:/home/dase-dis/拷贝到客户端:
scp -r /home/dase-dis/hadoop-2.10.1 dase-dis@ecnu04:/home/dase-dis/
其实打包一下拷贝会更加好的,这里偷懒了
启动HDFS服务
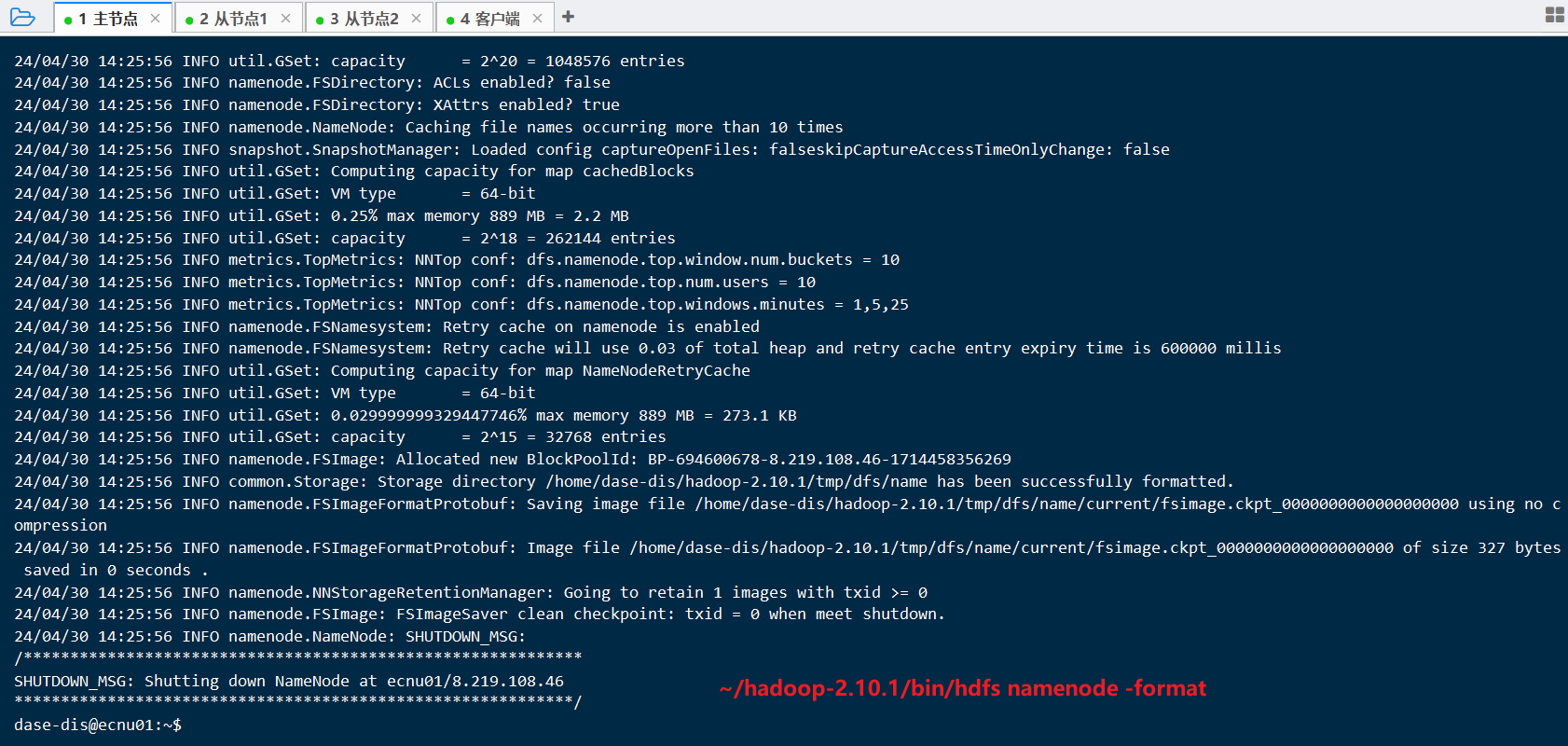
格式化
注意: 仅在第一次启动 HDFS 时才需要格式化 NameNode,如果是重启HDFS那么跳过这步,直接执行下一步即可。
此外,在进行 NameNode 格式化之前,如果~/hadoop-2.10.1/tmp/文件夹已存在,那么需要删除该文件夹后再执行以下格式化命令。如果启动时炸了,CTRL+C了,断电了,请参考后文解决办法,可能仍然需要格式化
- 格式化命令:
~/hadoop-2.10.1/bin/hdfs namenode -format
启动
- 启动:
~/hadoop-2.10.1/sbin/start-dfs.sh

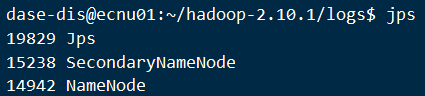
验证
验证:
jps主节点
- 从节点
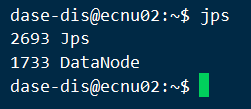
浏览器访问http://主节点IP:50070/,(如果主节点是云服务器记得把防火墙打开)
开防火墙:
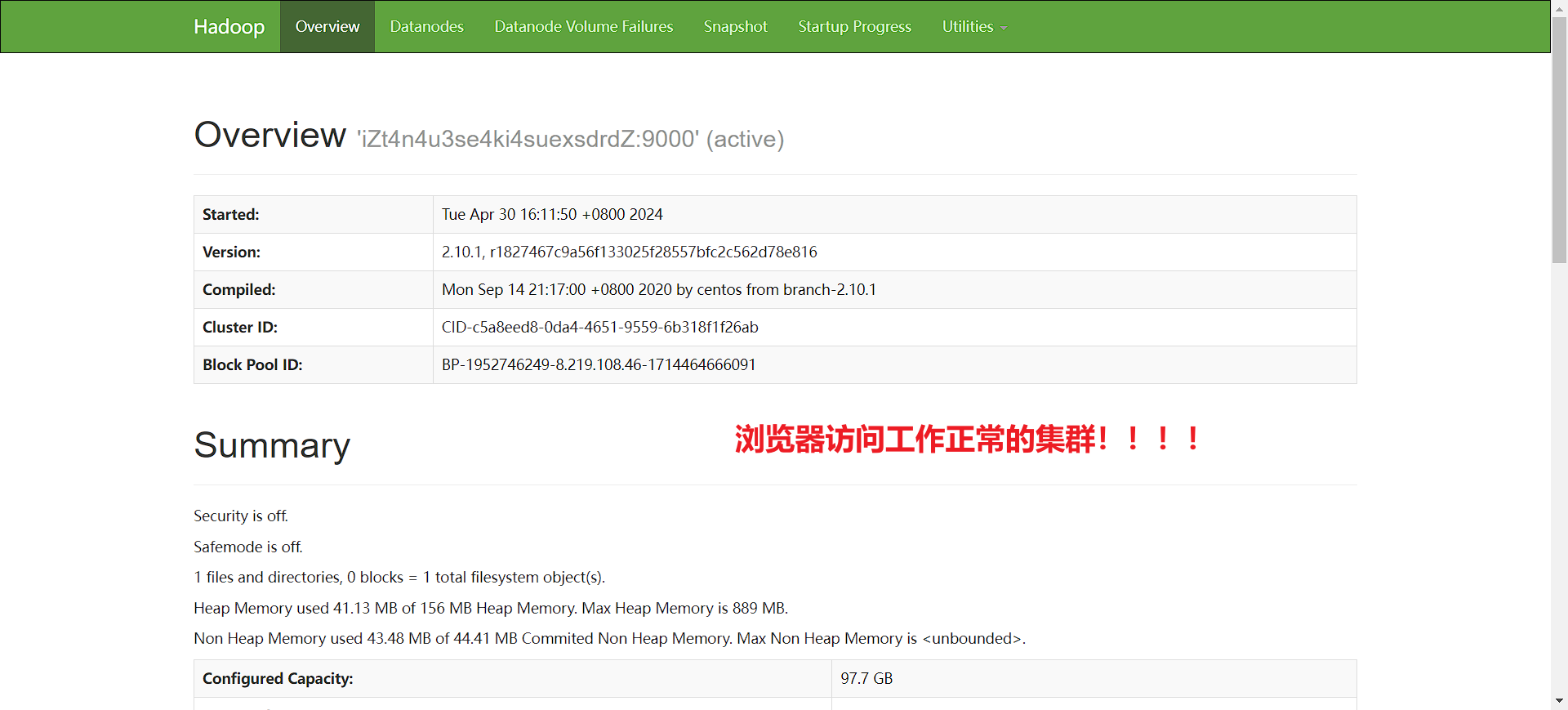
集群工作正常:
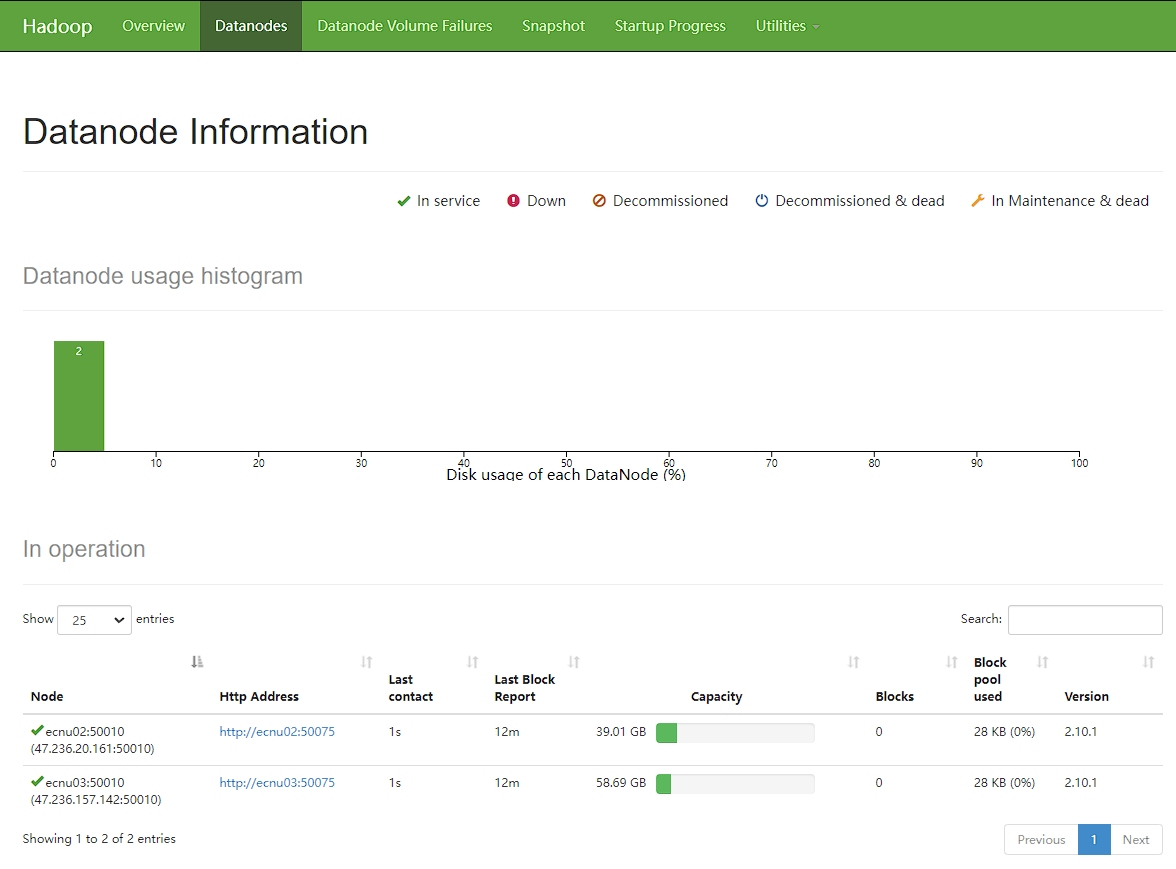
查看节点信息:
集群异常解决
- 如果因为一些情况导致集群第一次没有启动成功,请在主、从节点:
在主节点, 停止集群:
~/hadoop-2.10.1/sbin/stop-dfs.sh删除运行生成文件:
cd ~/hadoop-2.10.1/tmp/dfs && rm -rf *删除日志:
cd ~/hadoop-2.10.1/logs && rm -rf *解决端口占用:
sudo reboot在主节点, 重新执行格式化命令:
~/hadoop-2.10.1/bin/hdfs namenode -format
- 云服务器可能会出现的错误
- 错误日志:
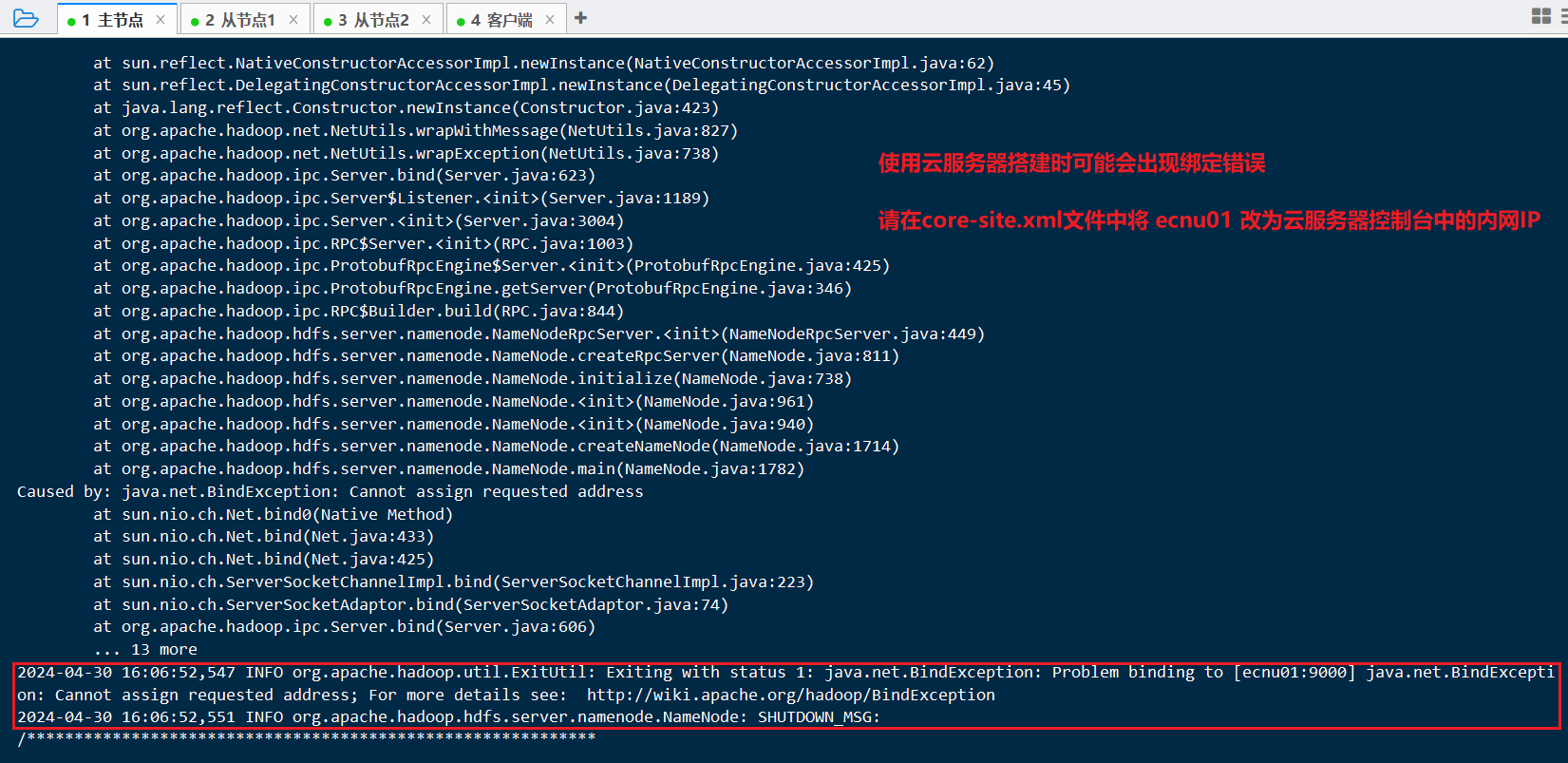
提示绑定错误或
2024-04-30 16:06:52,547 INFO org.apache.hadoop.util.ExitUtil: Exiting with status 1: java.net.BindException: Problem binding to [ecnu01:9000] java.net.BindException: Cannot assign requested address; For more details see: http://wiki.apache.org/hadoop/BindException的检查文章
spark-1中提到的hosts设置是否正确, 设置好了不会出现这种情况参考:
https://blog.csdn.net/xiaosa5211234554321/article/details/119627974
https://cwiki.apache.org/confluence/display/HADOOP2/BindException
HDFS Shell
注意:第一次使用 HDFS 时,需要首先在 HDFS 中创建用户目录
打开工作目录:
cd ~/hadoop-2.10.1为当前 dase-dis 用户创建一个用户根目录:
./bin/hdfs dfs -mkdir -p /user/dase-dis
HDFS Shell目录操作示例:
显示 hdfs:///user/dase-dis 下的文件:
./bin/hdfs dfs -ls /user/dase-dis新建 hdfs:///user/dase-dis/input 目录:
./bin/hdfs dfs -mkdir /user/dase-dis/input删除 hdfs:///user/dase-dis/input 目录:
./bin/hdfs dfs -rm -r /user/dase-dis/input
Spark部署
修改配置文件
修改.bashrc文件
客户端执行:
vi ~/.bashrc按
i进入编辑模式,按方向键到文件最后一行,输入export TERM=xterm-color
按
Esc键退出编辑模式,输入:wq保存退出使
.bashrc配置生效:source ~/.bashrc
下载 spark
在主节点执行:
启动HDFS服务(已经启动直接下一步):
~/hadoop-2.10.1/sbin/start-dfs.sh下载Spark安装包:
wget http://archive.apache.org/dist/spark/spark-2.4.7/spark-2.4.7-bin-without-hadoop.tgz解压安装包:
tar -zxvf spark-2.4.7-bin-without-hadoop.tgz改名:
mv ~/spark-2.4.7-bin-without-hadoop ~/spark-2.4.7
上述步骤完成后: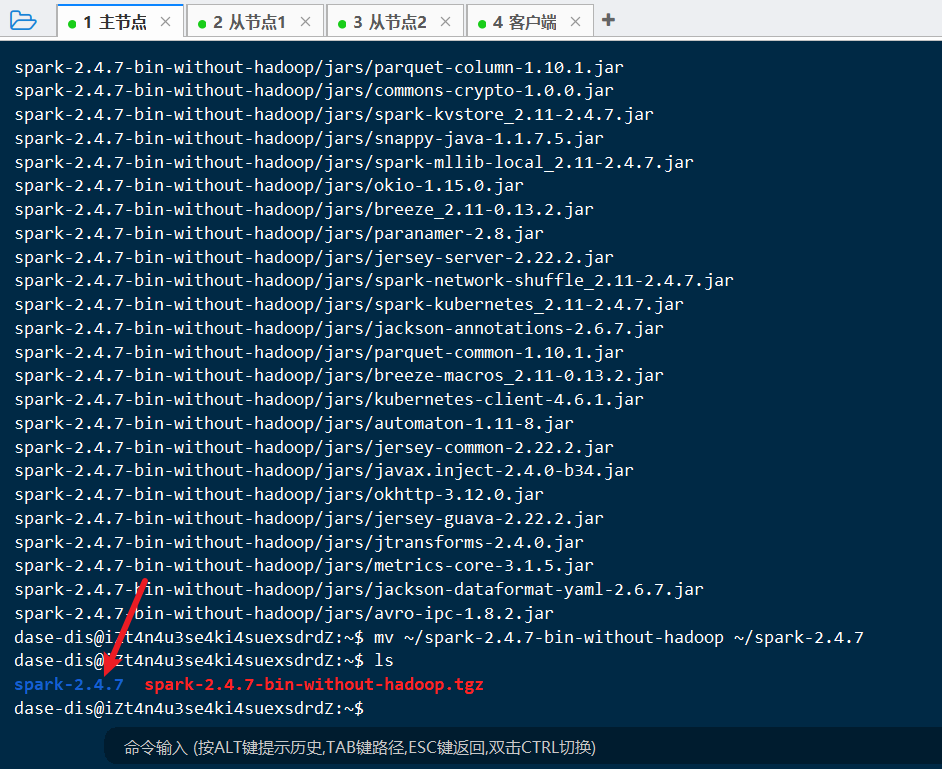
修改配置
在主节点执行以下修改:
spark-env
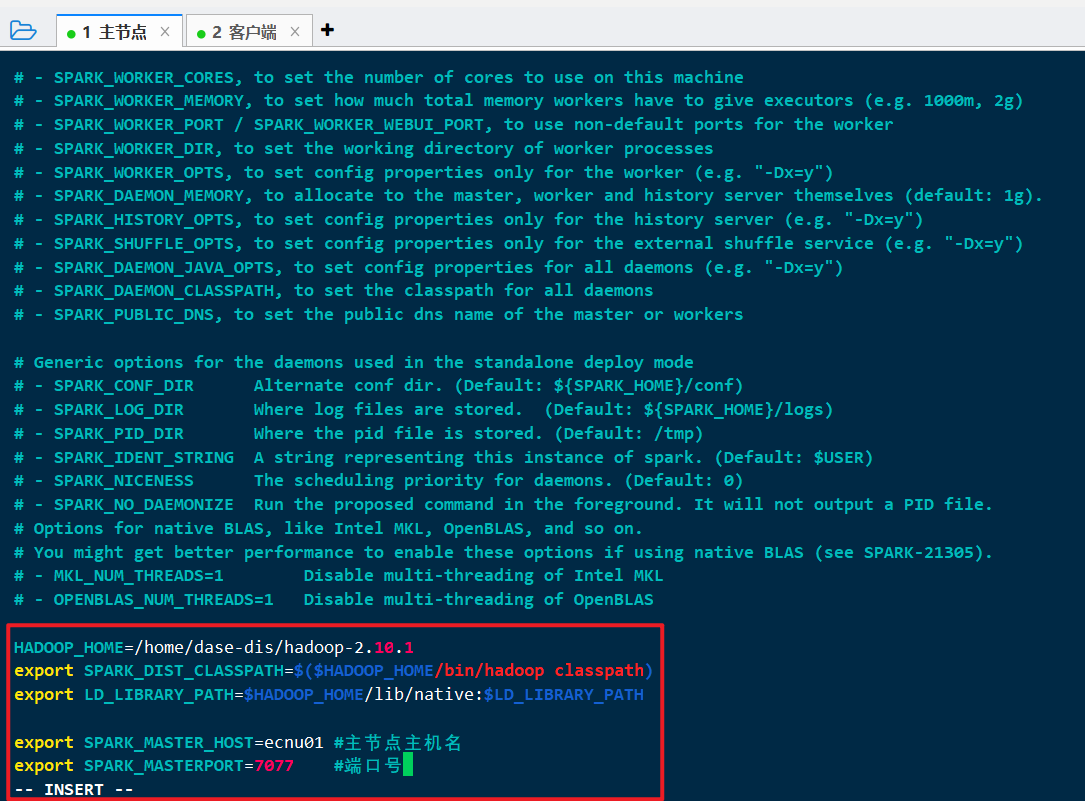
cp /home/dase-dis/spark-2.4.7/conf/spark-env.sh.template /home/dase-dis/spark-2.4.7/conf/spark-env.shvi /home/dase-dis/spark-2.4.7/conf/spark-env.sh
修改为:
1 | 因为下载的是Hadoop Free版本的Spark, 所以需要配置Hadoop的路径 |
slaves
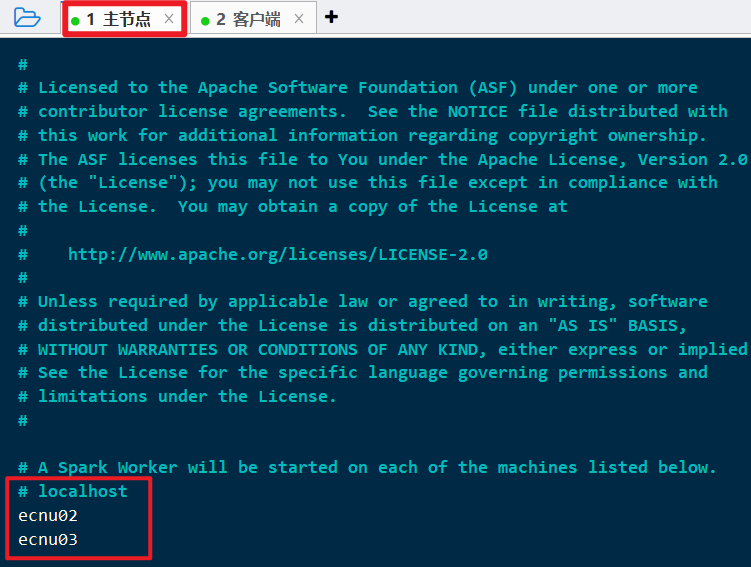
cp spark-2.4.7/conf/slaves.template spark-2.4.7/conf/slavesvi spark-2.4.7/conf/slaves
修改为:
1 | localhost |
spark-defaults
cp spark-2.4.7/conf/spark-defaults.conf.template spark-2.4.7/conf/spark-defaults.confvi spark-2.4.7/conf/spark-defaults.conf
修改为:
1 | spark.eventLog.enabled=true |
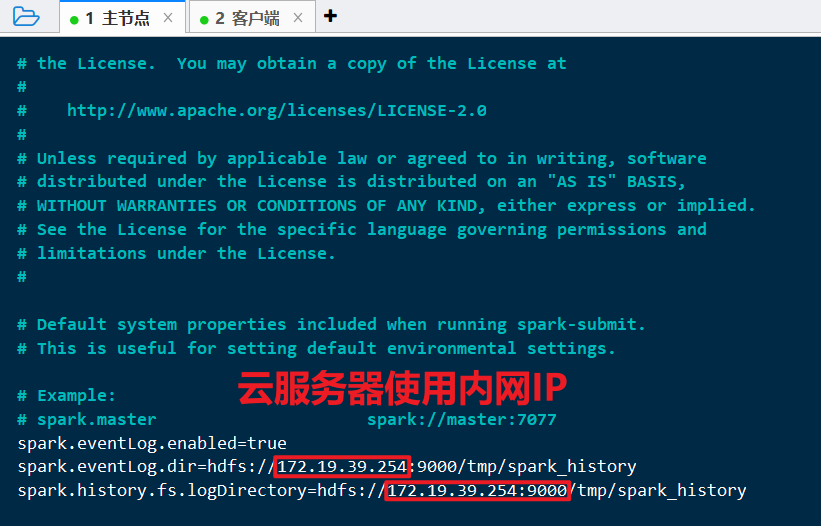
spark-config
vi spark-2.4.7/sbin/spark-config.sh
追加:
1 | export JAVA_HOME=/home/dase-dis/jdk1.8.0_202 |
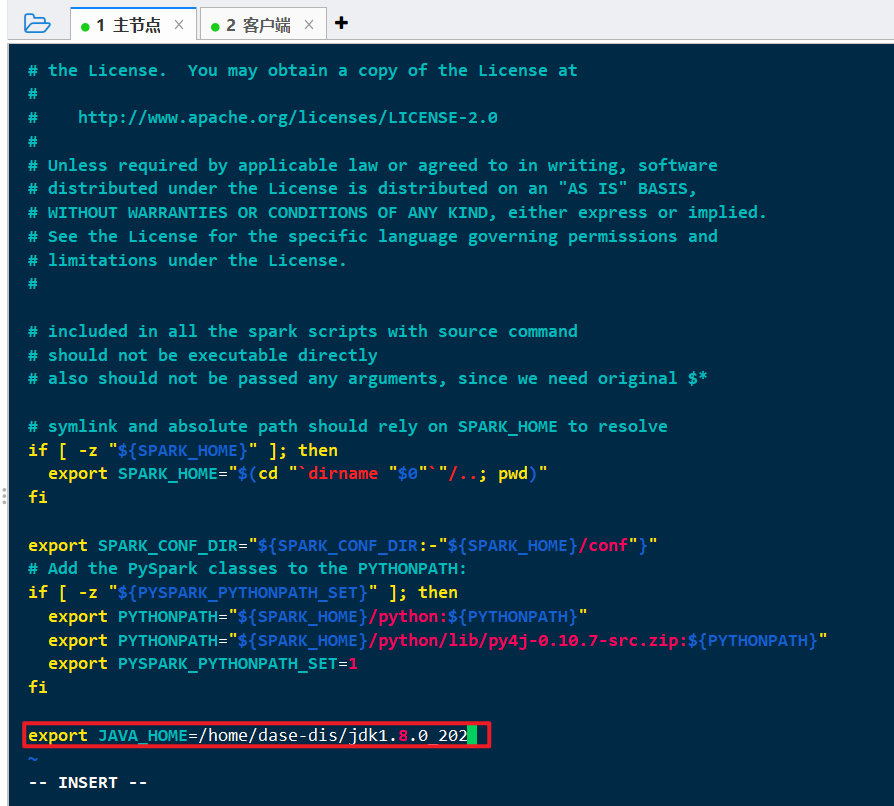
安装spark
拷贝
本步骤将spark修改好的安装包拷贝到其他三台机:
scp -r spark-2.4.7 dase-dis@ecnu02:~/scp -r spark-2.4.7 dase-dis@ecnu03:~/scp -r spark-2.4.7 dase-dis@ecnu04:~/
HDFS中建立日志目录
~/hadoop-2.10.1/bin/hdfs dfs -mkdir -p /tmp/spark_history
启动 spark
千辛万苦, 终于到启动了
在主节点执行:
启动spark:
~/spark-2.4.7/sbin/start-all.sh启动日志服务器:
~/spark-2.4.7/sbin/start-history-server.sh主节点:
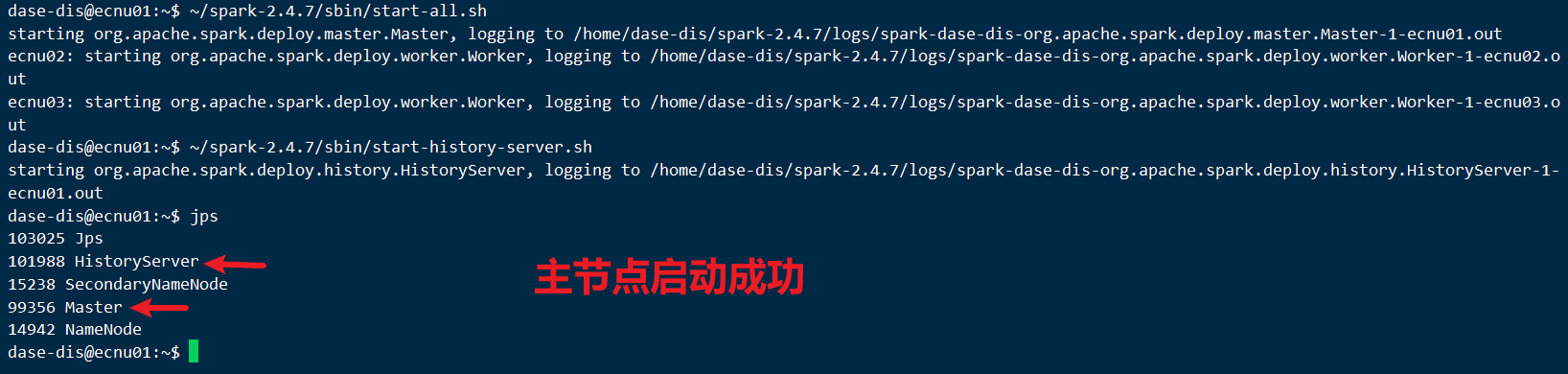
- 从节点:
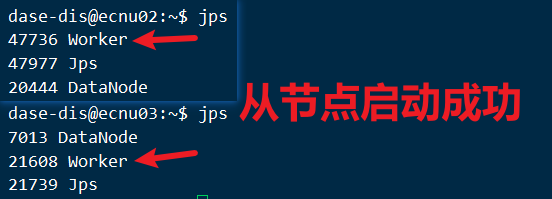
错误处理:
1 | dase-dis@ecnu01:~$ ~/spark-2.4.7/sbin/start-all.sh |
请检查hosts文件设置, 文章[大数据]Spark-1 SSH & JDK部署
验证
浏览器访问: http://主节点IP:8080/,(如果主节点是云服务器记得把防火墙打开)
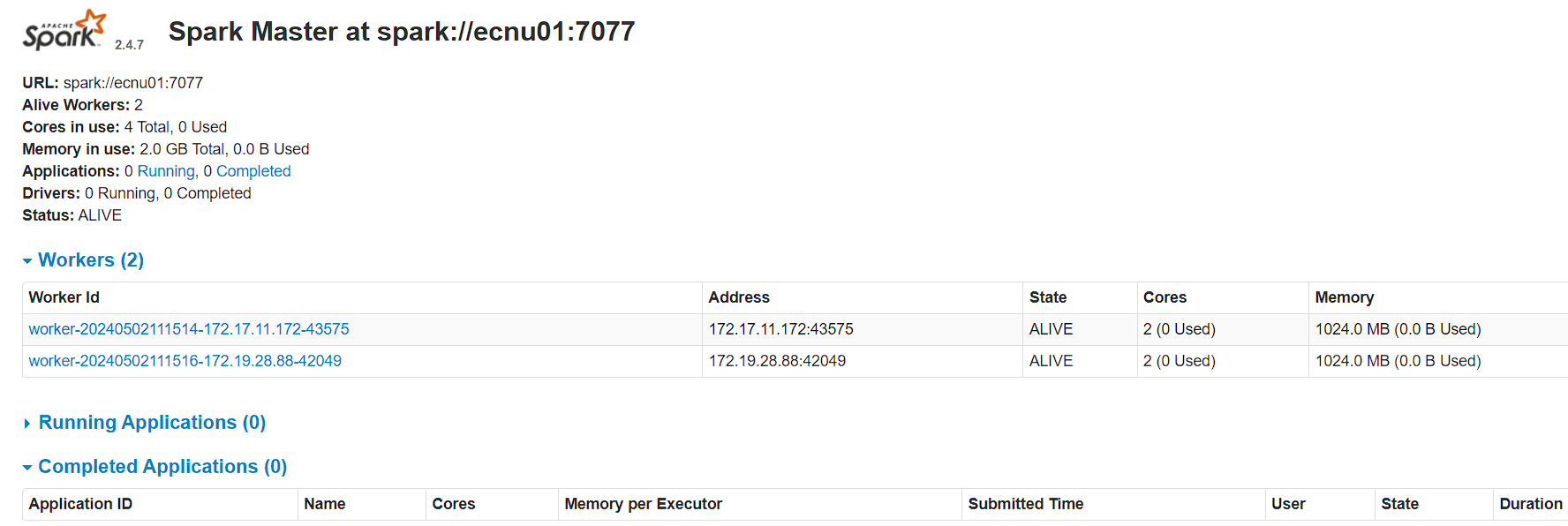
可以看到有两个worker在线, 大功告成
运行spark应用程序
好不容易搞好了, 来玩一下:
创建文件夹&上传文件
创建
spark_input文件夹:~/hadoop-2.10.1/bin/hdfs dfs -mkdir -p spark_input上传文件
RELEASE到spark_input:~/hadoop-2.10.1/bin/hdfs dfs -put ~/spark-2.4.7/RELEASE spark_input/
在hadood的页面可以看到, 文件RELEASE存储在两个节点中:
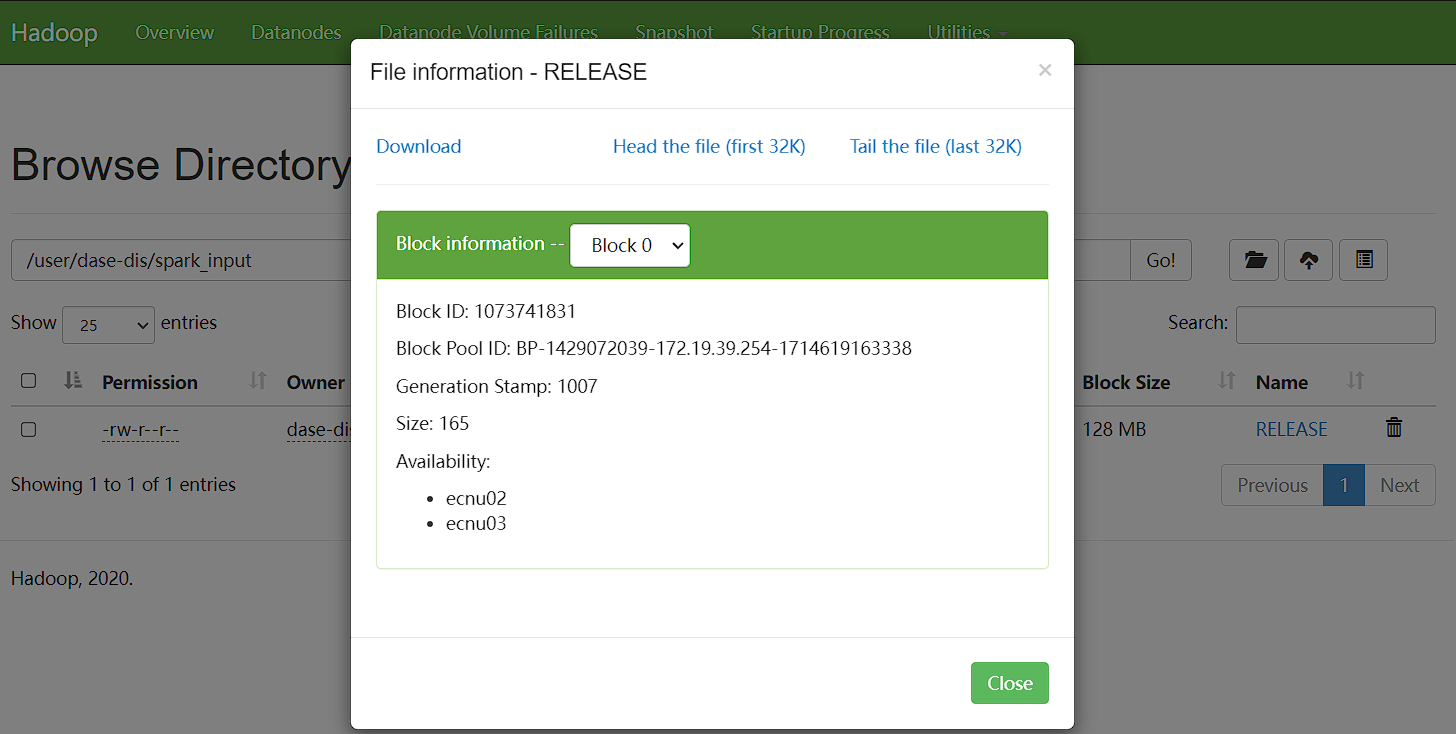
启动 Spark Shell
- 启动
spark-shell:~/spark-2.4.7/bin/spark-shell --master spark://ecnu01:7077
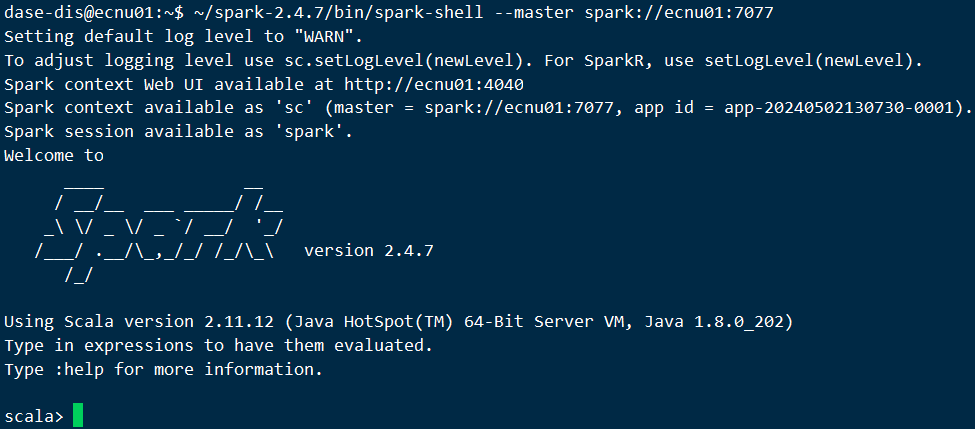
- 键入以下
Scala代码:
1 | val sc = spark.sparkContext |
shell输出:
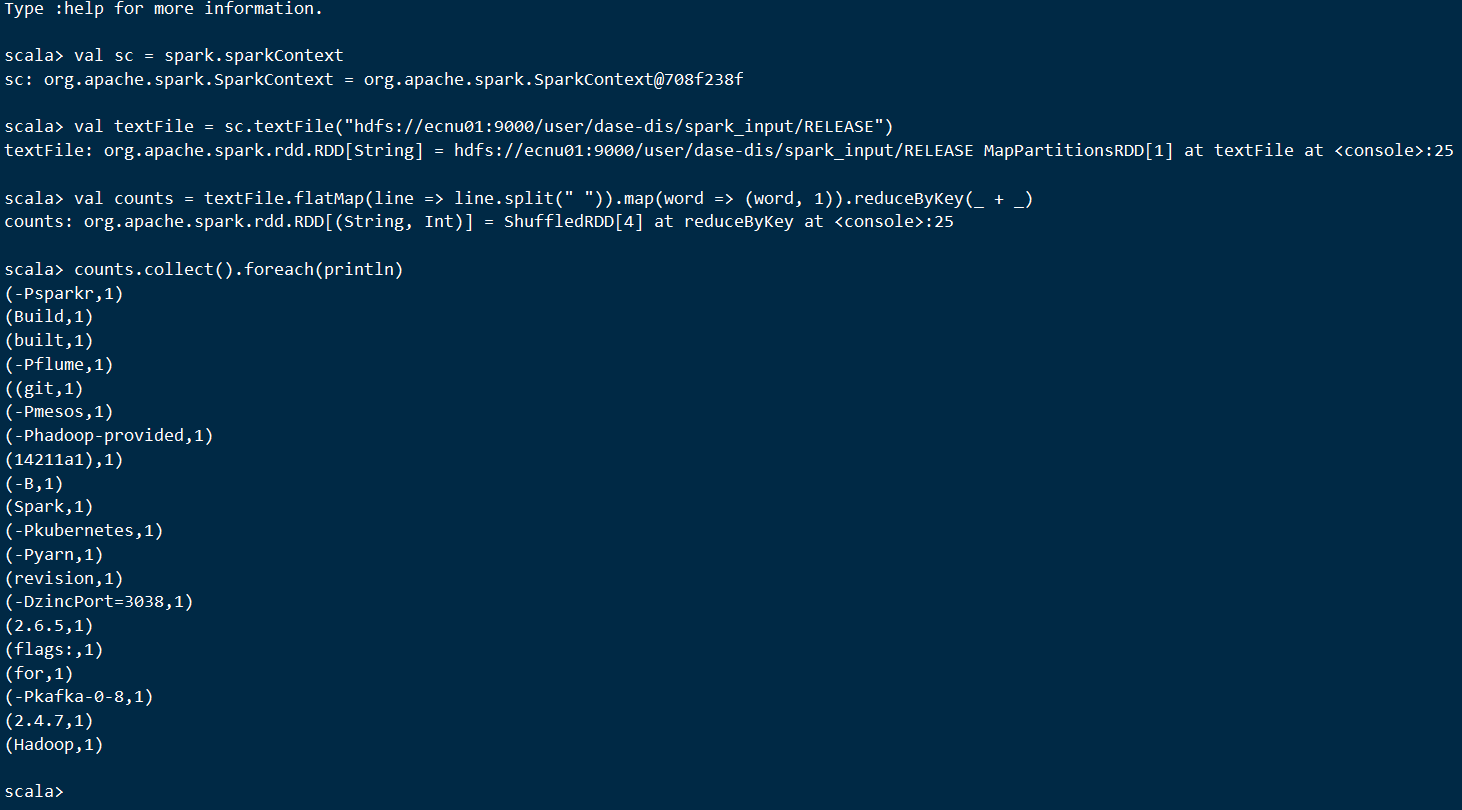
可以在网页查看到正在运行的任务信息:
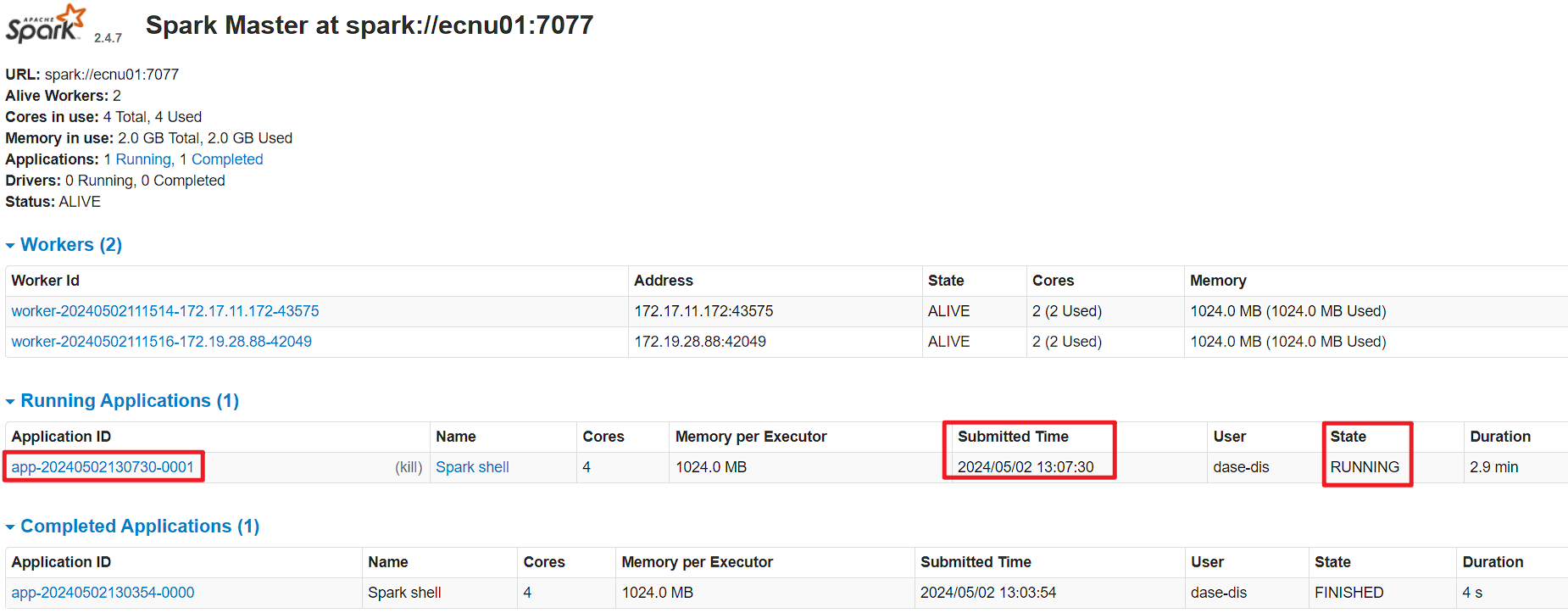
到此Spark集群就已经顺利搭建完毕了
停止集群
如果你希望停止集群:
停止
Spark:/spark-2.4.7/sbin/stop-all.sh停止
Spark日志服务:/spark-2.4.7/sbin/stop-history-server.sh停止
HDFS服务:/hadoop-2.10.1/sbin/stop-dfs.sh
测试运行
经典的WordCount程序源码如下:
1 | package cn.edu.ecnu.spark.example.java.wordcount; |
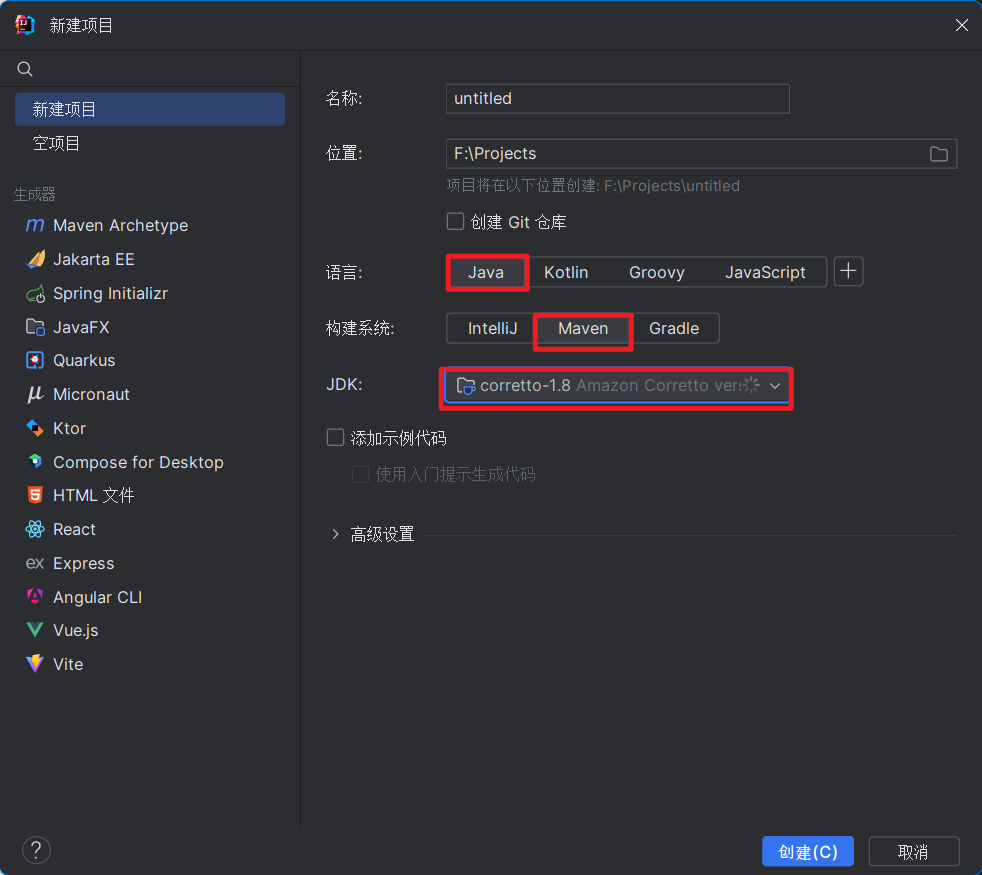
新建maven项目
- 在
idea新建项目:
pom.xml内容如下:
1 |
|
- 更新依赖
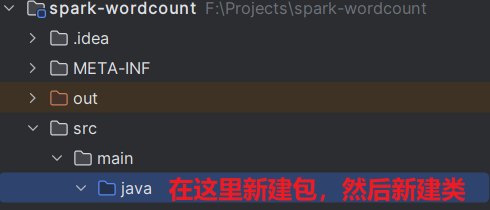
新建 Java 代码
- 新建包
cn.edu.ecnu.spark.example.java.wordcount,类WordCount:
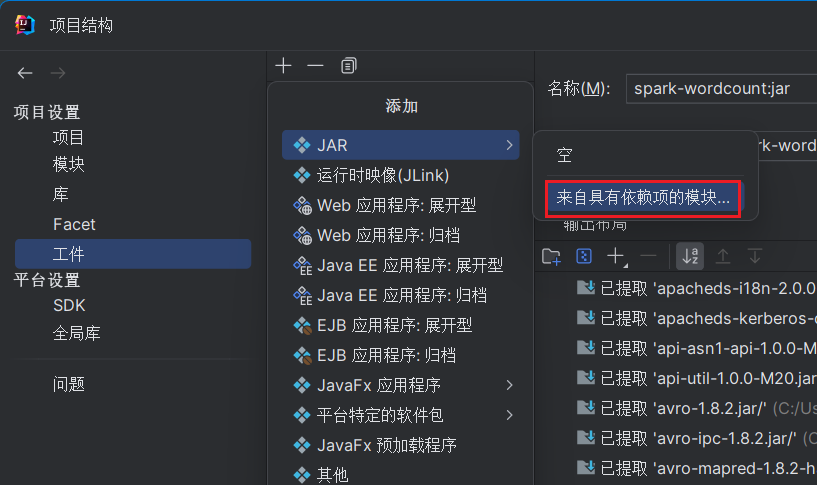
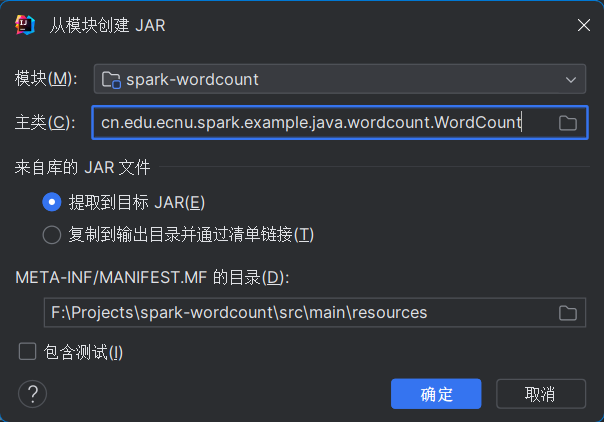
打包
- 打包为
.jar:
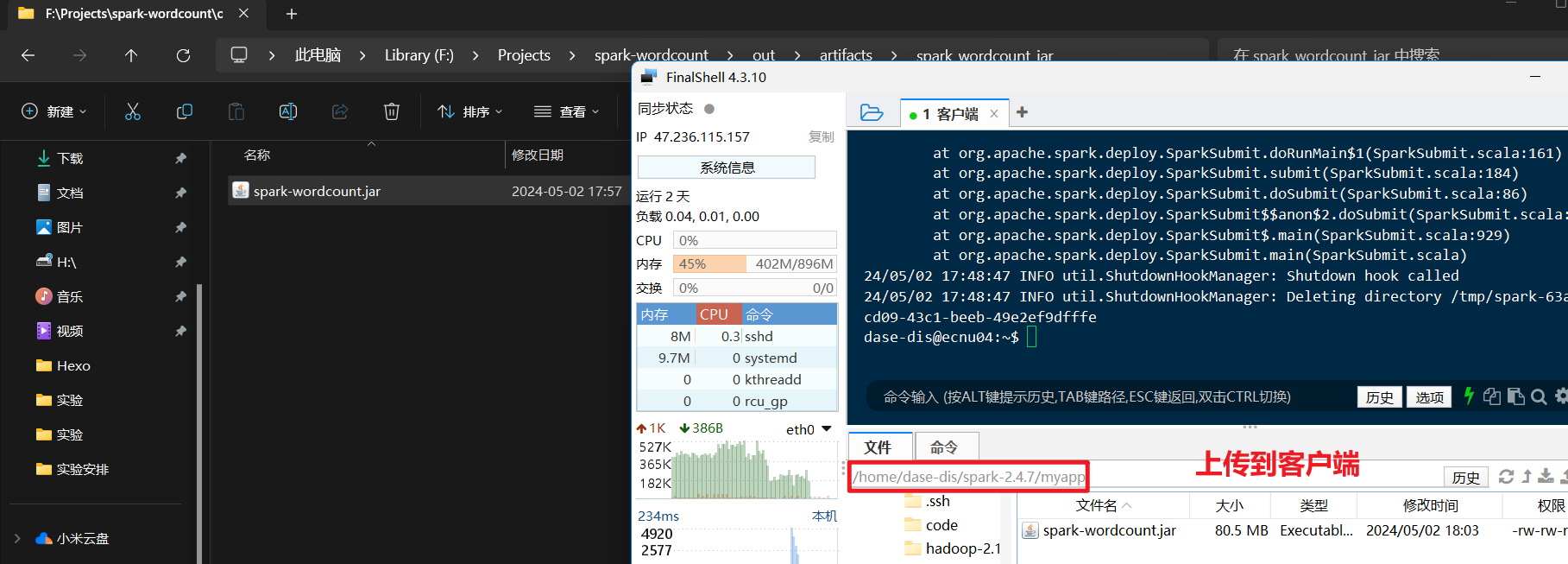
传送到客户端
- 将打包好的
.jar(位置项目路径\out\artifacts\spark_wordcount_jar)传到客户端的/home/dase-dis/spark-2.4.7/myapp
下载测试数据
下载:
wget https://github.com/ymcui/Chinese-Cloze-RC/archive/master.zip解压:
unzip master.zip解压:
unzip ~/Chinese-Cloze-RC-master/people_daily/pd.zip拷贝到集群:
~/hadoop-2.10.1/bin/hdfs dfs -put ~/Chinese-Cloze-RC-master/people_daily/pd/pd.test spark_input/pd.test
提交jar任务
删除输出文件夹:
~/hadoop-2.10.1/bin/hdfs dfs -rm -r spark_output提交任务:
~/spark-2.4.7/bin/spark-submit \ --master spark://ecnu01:7077 \ --class cn.edu.ecnu.spark.example.java.wordcount.WordCount \ /home/dase-dis/spark-2.4.7/myapp/spark-wordcount.jar hdfs://ecnu01:9000/user/dase-dis/spark_input hdfs://ecnu01:9000/user/dase-dis/spark_output
正在运行
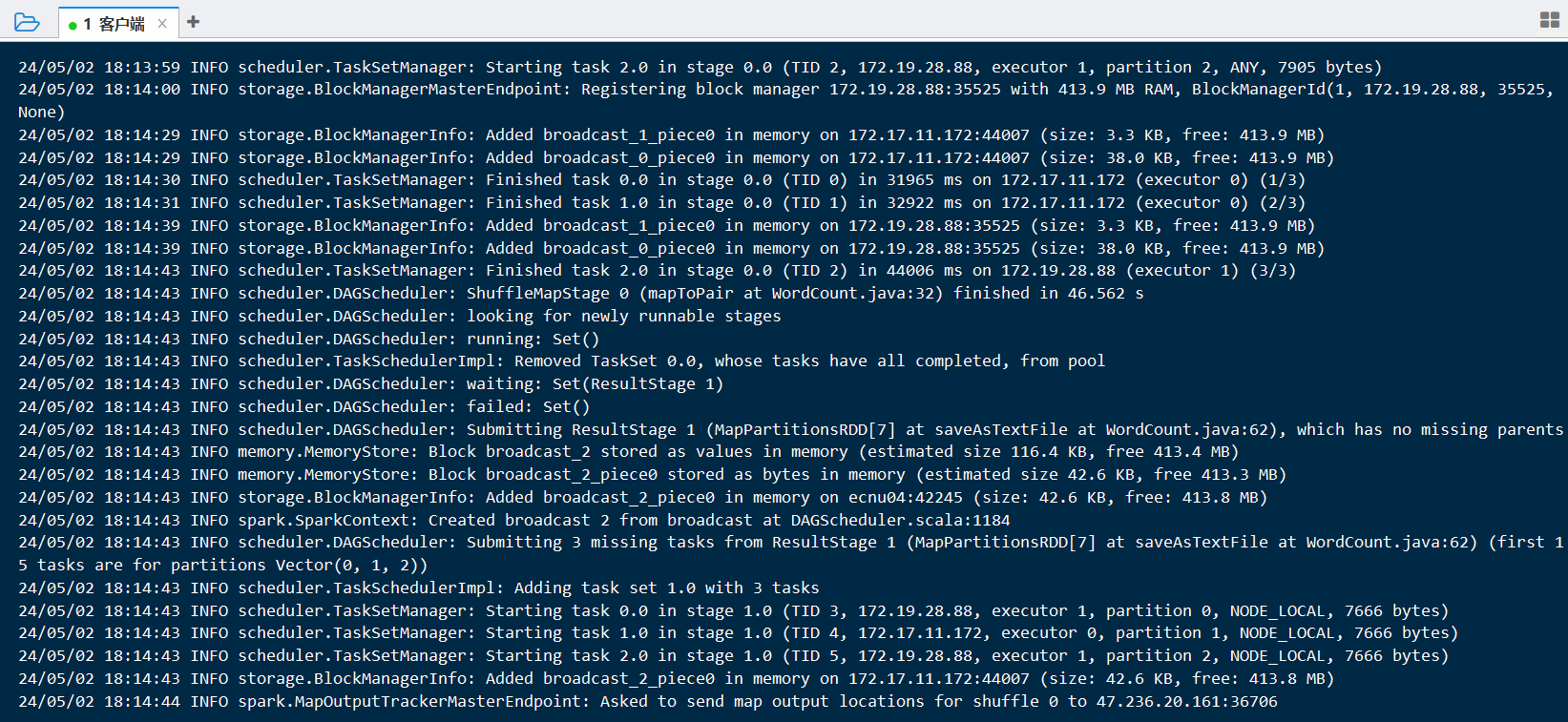
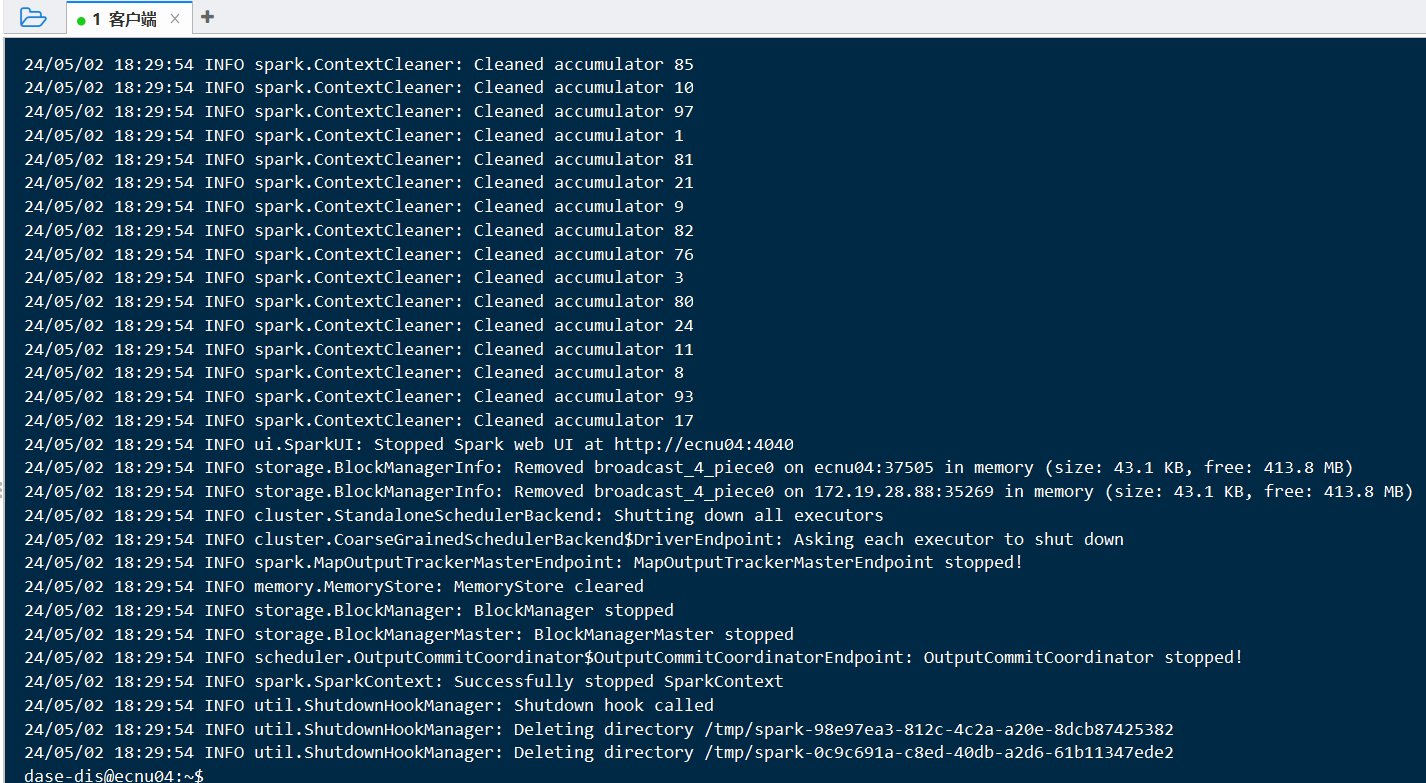
顺利跑完
ssh:
webui:
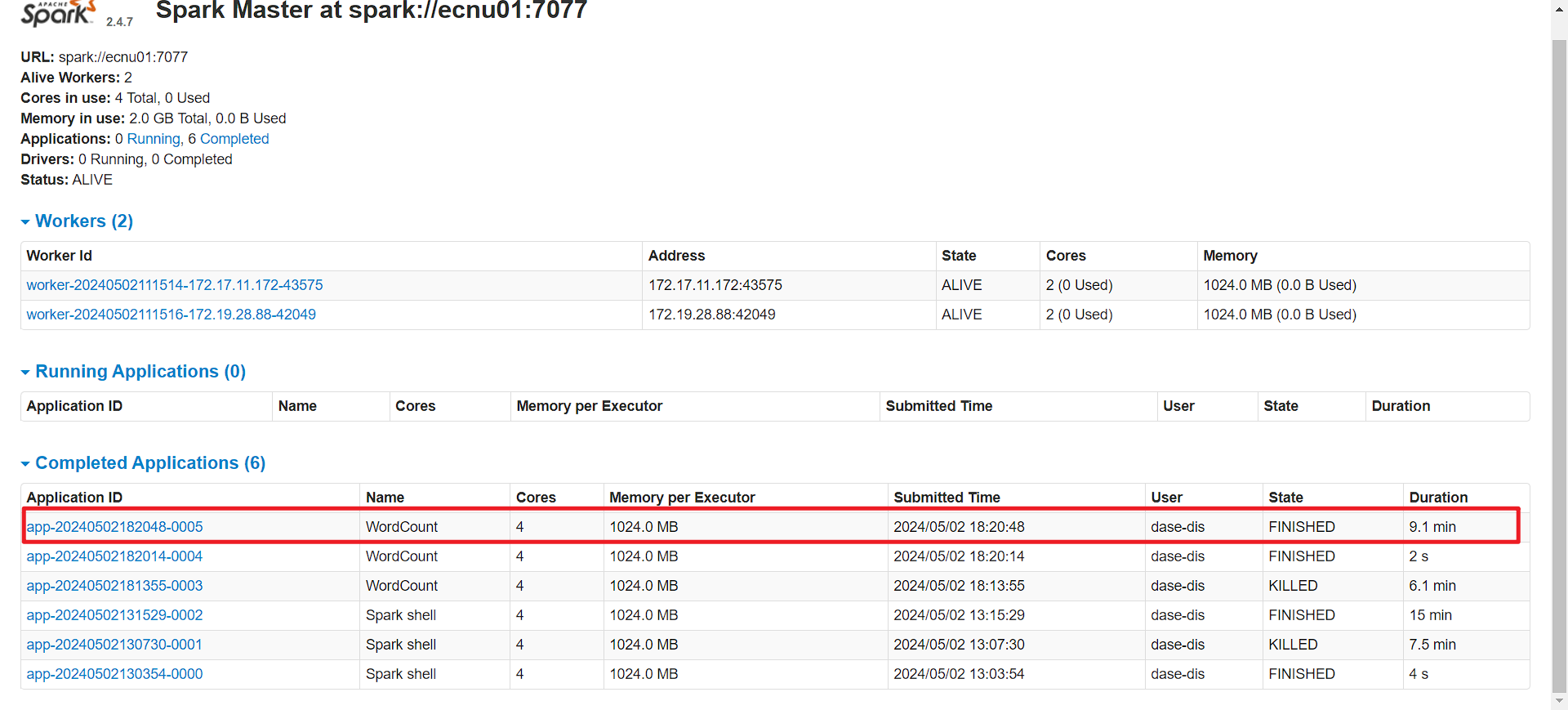
查看output文件夹:

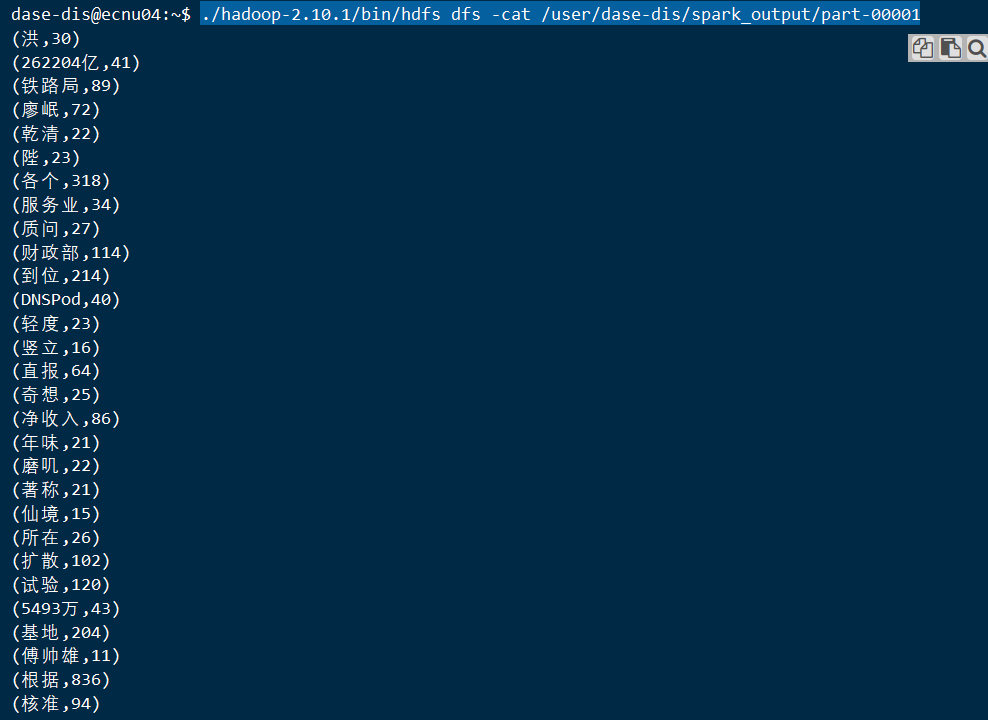
查看part01运行结果:
./hadoop-2.10.1/bin/hdfs dfs -cat /user/dase-dis/spark_output/part-00001