摘要
Current Large Language Models (LLMs) are not only limited to some maximum context length, but also are not able to robustly consume long inputs. To address these limitations, we propose ReadAgent, an LLM agent system that increases effective context length up to 20× in our experiments. Inspired by how humans interactively read long documents, we implement ReadAgent as a simple prompting system that uses the advanced language capabilities of LLMs to (1) decide what content to store together in a memory episode, (2) compress those memory episodes into short episodic memories called gist memories, and (3) take actions to look up passages in the original text if ReadAgent needs to remind itself of relevant details to complete a task. We evaluate ReadAgent against baselines using retrieval methods, using the original long contexts, and using the gist memories. These evaluations are performed on three long-document reading comprehension tasks: QuALITY, NarrativeQA, and QMSum. ReadAgent outperforms the baselines on all three tasks while extending the effective context window by 3.5 −20×.
当前的大语言模型(LLM)不仅受到最大上下文长度的限制,还无法稳定地处理超长输入。为解决这些缺陷,我们提出ReadAgent——一套大语言模型智能体系统,在实验中可将有效上下文长度提升至原来的20倍。
受人类交互式阅读长文档的方式启发,我们将ReadAgent设计为一个简洁的提示系统,利用大语言模型强大的语言能力实现三项核心功能:1. 确定哪些内容应整合为一个记忆单元进行存储;2. 将这些记忆单元压缩为简短的主旨记忆(gist memory);3. 当完成任务需要回忆相关细节时,主动执行检索操作,从原文中查找对应段落。我们将ReadAgent与多类基线方法进行对比,包括基于检索的方法、直接使用原始长上下文的方法,以及仅使用主旨记忆的方法。对比实验在三项长文档阅读理解任务上开展:QuALITY、NarrativeQA和QMSum。结果表明,ReadAgent在所有三项任务上均优于基线方法,同时将有效上下文窗口扩大了3.5至20倍。
方法
摘要记忆 Gist Memory
摘要记忆(gist memory)是原始长上下文中文本片段的简短摘要的有序集合。构建摘要记忆包含两个步骤:分页和记忆摘要生成,如下文分别描述。
剧情分页(Episode Pagination)
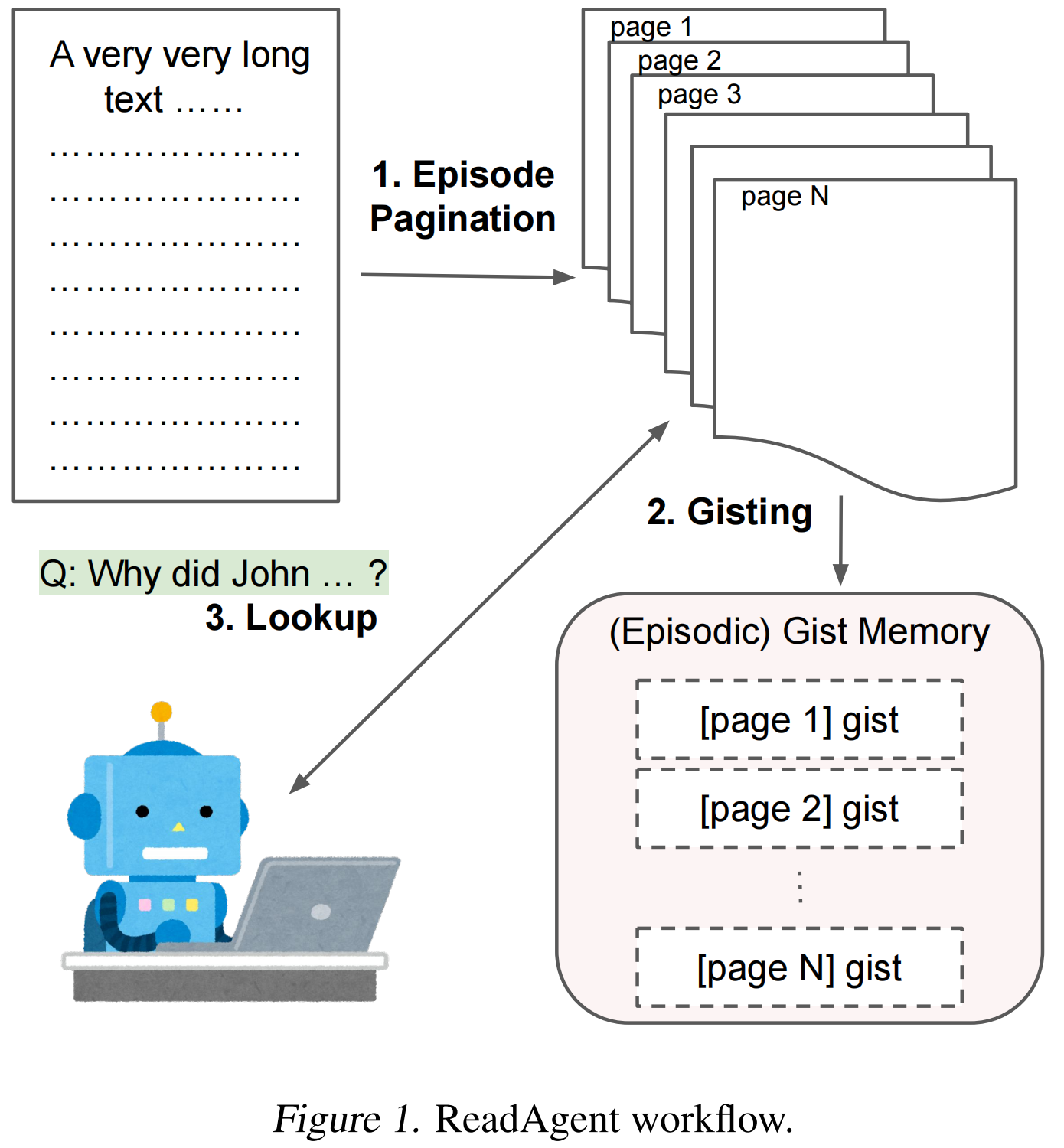
当 ReadAgent 阅读长文本时,它会通过在何处暂停阅读来决定将哪些内容存储为剧情分页(Episode Pagination)。在每一步中,我们向大语言模型(LLM)提供一段文本,该文本从上一次暂停点开始,直到达到最大词数限制为止。我们提示 LLM 选择一个段落之间的自然停顿点,然后将上次暂停点到当前暂停点之间的内容视为一个剧集(也称为一页)。这就是剧集分页,我们通过以下提示来实现这一机制。
如提示中所示,段落之间插入了可能的中断点,以带编号的标签表示(例如 ⟨13⟩),这使得该问题成为针对大语言模型的多选题。我们仅在达到 min words 后才开始插入这些带编号的标签,以确保每页至少包含 min words 个词。
1 | Pagination Prompt: |
1 | 你得到了一段文本,这段文本是从更大的文本(文章、书籍等)中提取的,并且在段落之间有一些带编号的标签。带编号的标签用尖括号表示。例如,如果标签编号是19,则在文本中显示为⟨19⟩。请你选择一个标签,在那里自然地中断阅读。 |
记忆概括 Memory Gisting
对于每一页,我们提示大型语言模型将确切内容缩短为一个摘要或要点,如下所示。
1 | Gisting Prompt: |
1 | 请缩短以下段落。 |
随后,在每个摘要前添加一个页面标签(例如“⟨第2页⟩\n{摘要内容}”),以对其进行上下文标注(说明摘要来源),然后将所有摘要连接起来。这样就得到了摘要记忆。我们在提示中使用“缩短”一词来生成这些摘要,因为它有助于保持叙述流程的自然性,使连接后的结果更流畅。在我们的实验中,使用“总结”一词则倾向于生成结构化的摘要。
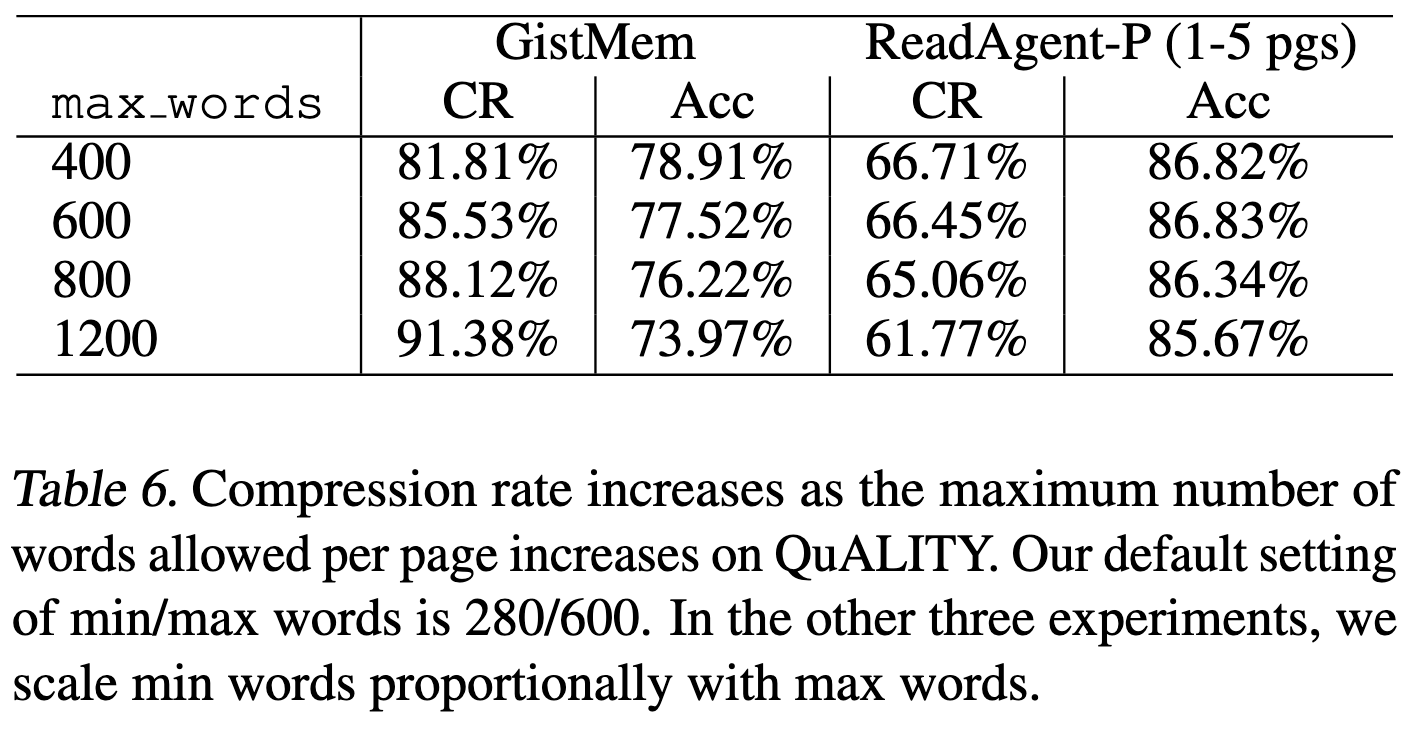
原始页面大小是决定摘要压缩程度的关键因素。假设我们将最小文本单位视为一个段落。直观上,一个段落与其相邻段落之间可能存在一定的互信息。因此,我们组合的文本块越大,可以去除的重复信息就越多。经验上,使用大语言模型压缩更大的文本块也往往会去除更多细节,这可能影响性能。我们通过调整分页中的最小字数和最大字数来控制页面大小。
这种权衡在4.4节中进行了研究,如下:
压缩权衡表6展示了随着页面尺寸增大,压缩率提高的经验结果。随着压缩率的降低,摘要对于直接回答问题更有用。然而,对于使用查找功能的ReadAgent,当初始摘要压缩率过高时,准确性会受到影响。
文章中各项任务使用的页面大小如下:

交互式查找与应答 Interactive Look-Up and Response
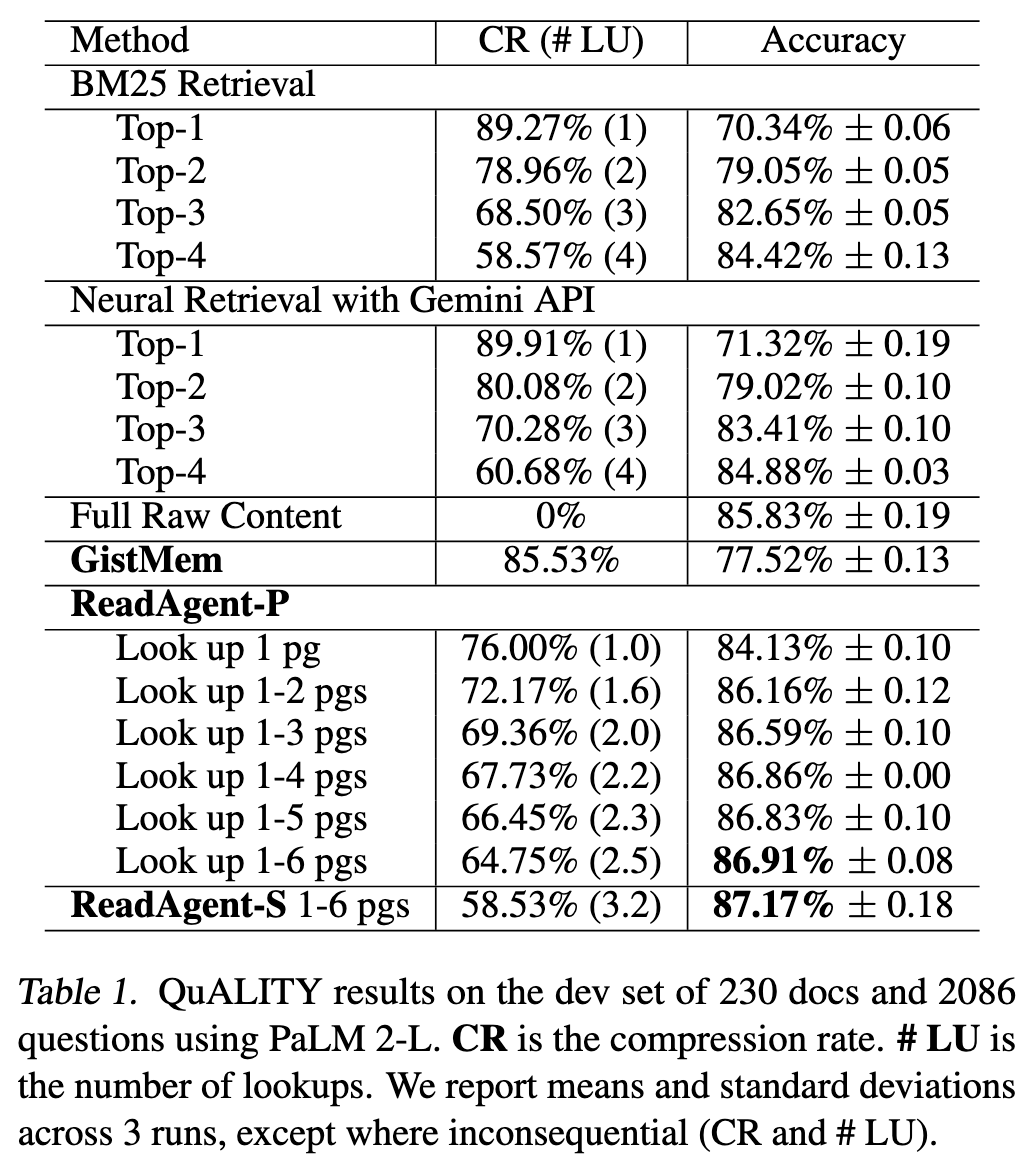
针对给定的长文档任务,我们希望 ReadAgent 在利用主旨记忆的基础上,进一步执行检索操作,从原文中查找相关细节。由于主旨记忆已通过页码完成上下文关联,我们只需对大语言模型进行提示,使其根据具体任务给出希望检索并重新阅读的页码。下文将讨论两种检索策略:并行一次性检索所有目标页面(ReadAgent‑P) 与串行逐次检索单页(ReadAgent‑S)。
ReadAgent-P(并行检索)
如下方所示的问答任务提示示例,我们通常会设定模型可检索的最大页面数量,同时要求模型尽可能少地选取页面,以避免不必要的计算开销与干扰信息。以下提示展示了并行检索的实现方式:模型仅需接收一次提示,即可同时请求多个页面。
1 | The following text is what you remember from reading |
1 | 以下文本是你阅读一篇文章后记住的内容,以及一道与之相关的选择题。你可以重新阅读这篇文章的 1 至 5 页内容来唤醒记忆,以便作答。请回复你想要重新阅读的页码。 |
被选中的原始页面会替换记忆中对应位置的主旨内容,同时保留整体的叙事逻辑。随后我们将任务与更新后的记忆再次输入大模型,提示其完成任务(示例提示词见附录 F)。
ReadAgent-S(串行检索)
我们还研究了串行检索策略:模型每次只请求一页,最多可检索设定的最大页面数。在串行检索中,模型在决定下一页要展开的内容前,能够先看到已经展开的页面。这让模型比并行检索获得更多信息,因此在部分场景中表现可能更优。但与模型的交互次数大幅增加会提升计算成本,所以串行检索仅适用于能带来明显收益的任务。
1 | The following text is what you remember from reading |
1 | 以下是你阅读一份会议记录后记住的内容,随后是一道与该记录相关的问题。 |
计算代价权衡与可扩展性 Computational Trade-offs and Scalability
篇章分段、主旨压缩与交互式检索都需要迭代推理。正如后文所示,其额外开销受一个较小系数的线性约束,这使得本方法能够随输入长度良好扩展。
分段:理论上,大语言模型可单次通读文档并直接完成分段,因此模型必须处理的最小词量等于文档长度。本文的分段算法将文档切分为不超过最大词数(max_words)的块,并保证每一步至少处理最小词数(min_words)。因此,最大词数与最小词数的比值,给出了模型使用该算法所需处理文档词数的倍数上限。
主旨压缩:主旨压缩需要对原始输入再做一次完整遍历,因为每一页均独立压缩。
检索:并行检索基于主旨而非全文,因此处理长度远短于原始输入的一次遍历。串行检索的每一步与并行检索类似,总开销受允许的最大检索次数限制。
作答:最终的任务作答环节与并行检索的计算量相近。当然,提示词模板会带来少量额外开销。
另一方面,主旨生成是一次性开销,而检索与作答环节主要处理远短于原文的主旨。当同一上下文被用于多个任务时,这部分一次性开销可被均摊。因此在这类场景下,ReadAgent能够减少模型需处理的总token数。
具体而言,直接基于QuALITY开发集原文(230篇文章、2086个问题)作答时,模型需处理8,708,434个词;而使用ReadAgent:
- 单页检索:6,499,856个词(节省25.4%)
- 最多2页检索:6,933,357个词(节省20.4%)
- 最多5页检索:7,503,084个词(节省13.8%)
可以预期,压缩率越高,节省的计算量越显著。
ReadAgent 的变体 ReadAgent Variants
在附录 G 中,我们讨论了ReadAgent 的多种变体,这些变体可适用于不同的问题场景,包括在阅读长文档之前就已知晓目标任务的情况。在附录 E 中,我们介绍了如何将 ReadAgent 适配应用于网页导航场景。
G.1 无条件 / 有条件 ReadAgent
在处理长文本时,用户有可能提前知道需要完成什么任务。这种情况下,我们可以在主旨生成环节的提示词中加入任务描述。这样一来,大语言模型就能更好地过滤掉与任务无关的信息,从而提升效率、减少干扰。这种方法被称为条件式 ReadAgent。
但更常见的情况是:生成主旨时并不知道具体任务,或者这些主旨需要用于多个不同任务(比如回答关于同一文本的多个问题)。因此,在主旨生成阶段不加入任务信息,模型可以生成通用性更强的主旨,代价是压缩率降低、干扰信息增多。这种设置被称为无条件式 ReadAgent。
本文仅对无条件式进行了实验验证,但我们认为在某些场景下,条件式会是更优选择。
G.2 特定领域专用 ReadAgent
与附录 G.1 相关,当将 ReadAgent 应用于特定领域时,提供领域专属指令往往会很有帮助。例如,若要使用 ReadAgent 理解程序库,可以向大语言模型给出更具体的指令,让其从每个文件中提取代码用途、功能、关键函数或类的签名等摘要信息作为主旨。
G.3 迭代主旨压缩(Iterative Gisting)
对于非常长的事件历史(例如一段对话),我们可以考虑通过迭代式主旨压缩对更早的记忆进行进一步压缩,从而支持更长的上下文,这与人类对久远记忆会变得模糊的特点相似。尽管这不在本文的研究范围内,但它对于智能助手等应用场景可能十分有用 —— 在这些场景中,随着用户与智能体持续交互,上下文长度会随时间无限增长。
实验结果
QuALITY
Quality: Question answering with long input texts, yes!
QuALITY 是一个四选项多选题问答评测任务,其文本数据来源于多个不同领域。该任务使用准确率作为评估指标,随机猜测的正确率为 25%。
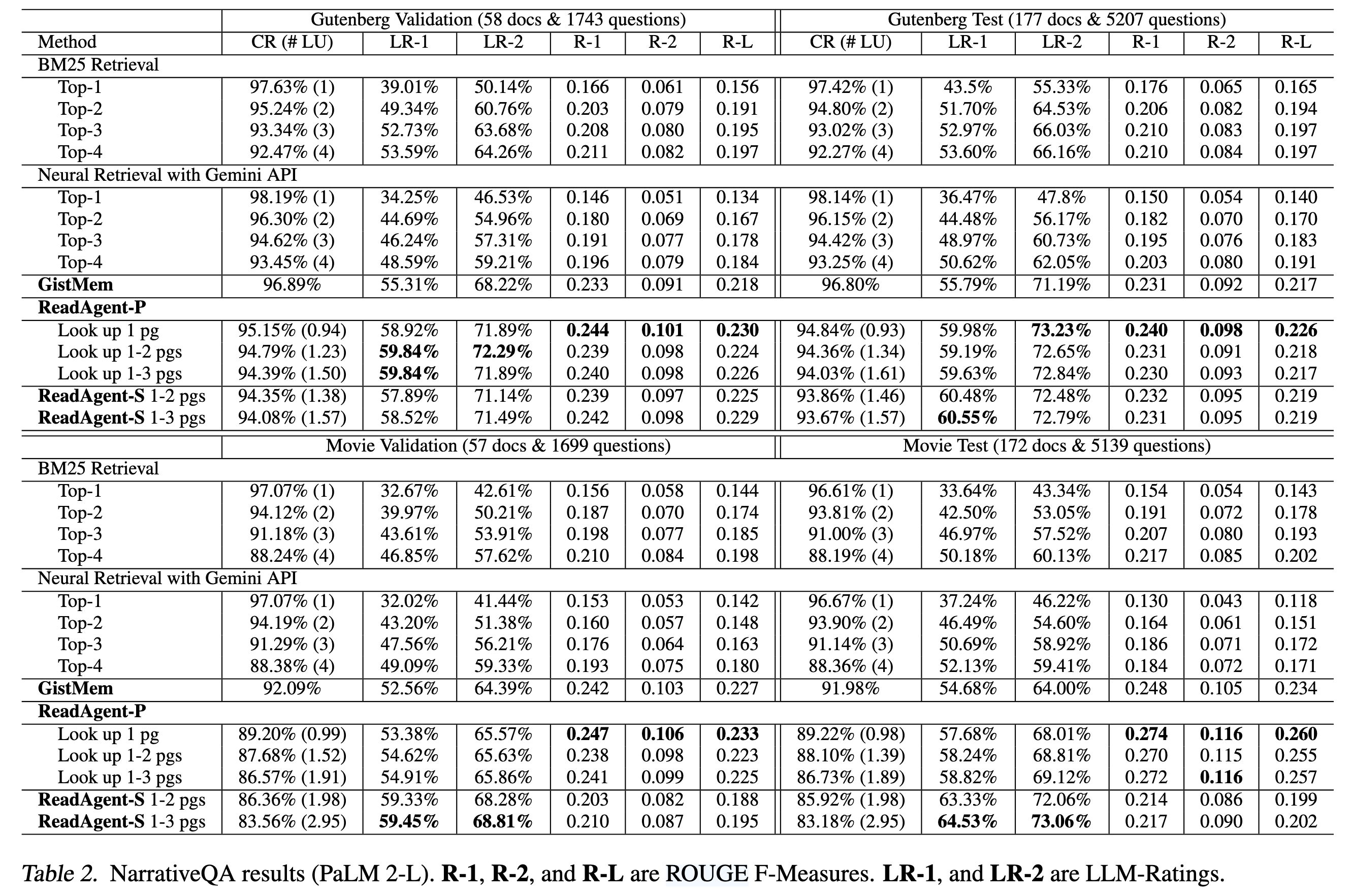
NarrativeQA
The NarrativeQA Reading Comprehension Challenge
NarrativeQA是我们选用的三个阅读理解数据集中平均上下文长度最长的数据集。该数据集分为书籍(古登堡)和电影剧本两部分。其中,古登堡测试集平均长度为 70619 词,最长达 343910 词;电影剧本测试集平均长度为 29963 词。
QMSum
QMSum: A New Benchmark for Query-based Multi-domain Meeting Summarization
SCROLLS: Standardized CompaRison Over Long Language Sequences
QMSum 由各类主题的会议记录以及对应的问题或指令构成。我们使用了由 SCROLLS(Shaham 等人,2022)提供的拼接版 QMSum 数据集。这些会议记录通常篇幅较长,长度在 1000 到 26300 词之间,平均约为 10000 词。图 5 展示了 QMSum 训练集的词数分布直方图。该任务的答案为自由文本格式,因此标准评估指标是 ROUGE F 值。