摘要
为了实现长期的人机交互,对话智能体需要持续地记忆所感知的信息,并在生成回复(response generation, RG)时能够恰当地检索这些信息。以往研究多关注通过移除过时记忆来提升检索质量,但我们认为,这类记忆在长期对话中能够为回复生成提供丰富且重要的上下文线索(例如用户行为的变化)。
本文提出了 THEANINE,一个基于大语言模型(LLM)的终身对话智能体框架。THEANINE 摒弃了记忆删除机制,而是通过基于时间关系与因果关系对大规模记忆进行关联式管理。在这种关联结构的支持下,THEANINE 通过引入“记忆时间线”(memory timelines)来增强回复生成能力——即由一系列记忆构成的序列,用于刻画相关历史事件的演化过程或因果关系。
此外,本文还提出了 TeaFarm,一种基于反事实驱动的评估方案,用于弥补 G-Eval 以及人工评估在衡量智能体将历史记忆整合进回复生成过程中的能力方面的不足。
引言
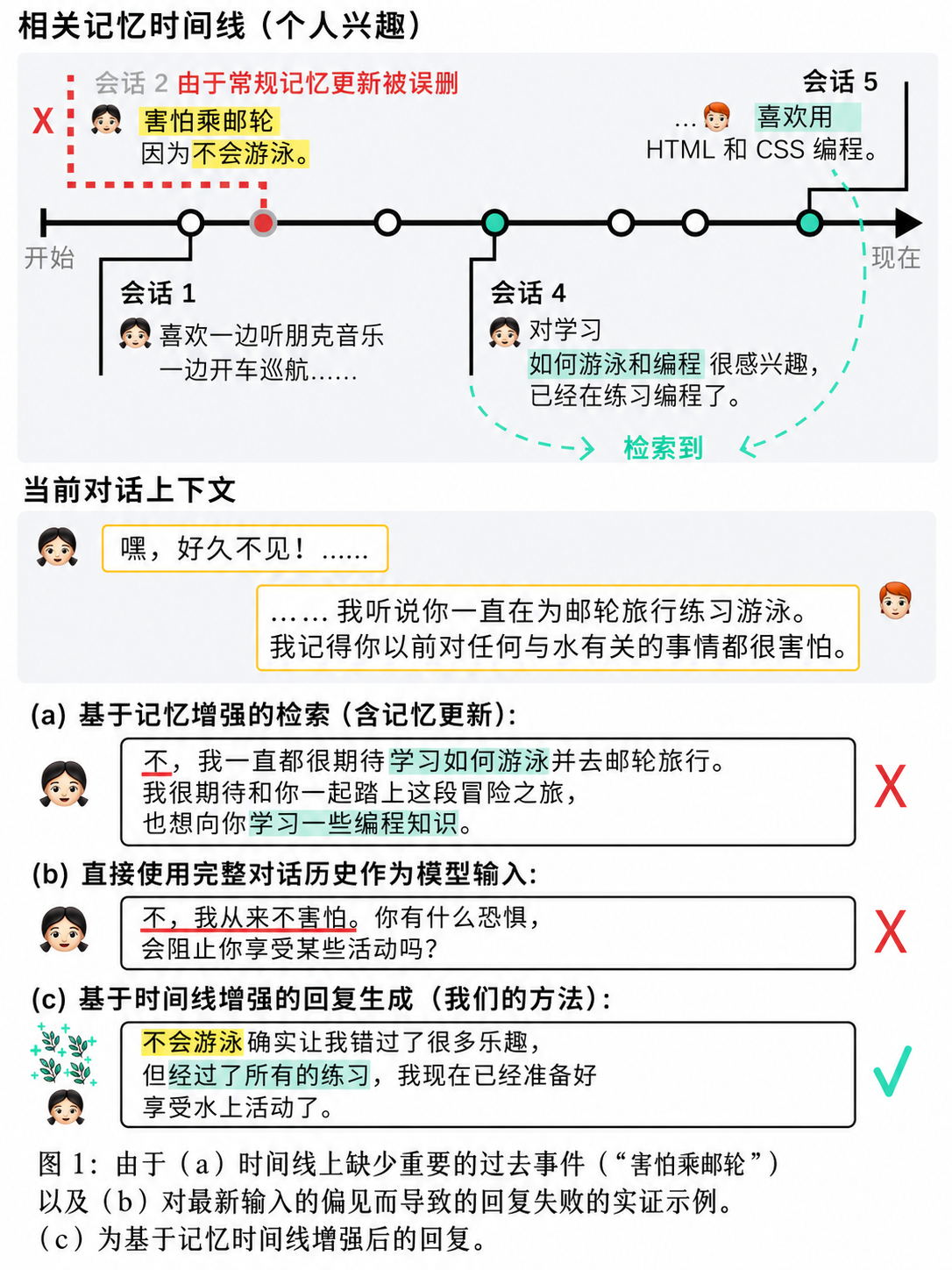
一种具有代表性的方法是将过往对话压缩为摘要式记忆,并在后续交互中检索这些记忆以增强回复生成(response generation, RG)(Xu et al., 2022a;Lu et al., 2023)。然而,随着对话不断累积,记忆规模的增长会对检索质量产生负面影响。尽管可以通过更新旧记忆在一定程度上缓解这一问题(Bae et al., 2022;Zhong et al., 2024),但这种常见做法往往会导致严重的信息丢失。
如图1(a)所示,在记忆更新时间线中,较早的一条关键记忆(例如一个重要的人设信息:“害怕船只”)被移除,从而导致回复生成不当。另一方面,利用近期大语言模型所具备的大上下文窗口来处理全部对话历史或记忆,虽然可以避免信息丢失¹,但往往会使模型对最新用户输入产生偏置性关注(见图1(b)),进而忽略过去相关的重要上下文(Liu et al., 2024)。
这些现象揭示了构建终身对话智能体所面临的两个核心挑战:
- (i)记忆构建(Memory construction):如何在不删除旧记忆的前提下,有效存储大规模历史交互信息?
- (ii)回复生成(Response generation):在不断增长的记忆空间中,如何识别与当前对话最相关的上下文线索,以生成恰当的回复?
受上述问题的启发,我们提出将这两个挑战分别但互补地加以解决:
(i)通过放弃记忆更新机制以避免信息丢失,并以一种关联结构在时间线上保留相关记忆;
(ii)将整条时间线作为整体进行检索,从而在不断扩展的搜索空间中更好地捕捉相关记忆。
基于这一思路,我们提出了 THEANINE,一个用于支持终身对话智能体的框架。
在记忆构建阶段(Phase I),不同于将原始记忆句子简单堆叠(Xu et al., 2022a)——这种方式由于信息结构松散,可能会影响记忆检索效果及回复质量(Mousavi et al., 2023;Chen et al., 2023)——THEANINE 将记忆存储为一个有向图结构。在该图中,受人类记忆机制的启发(即人们倾向于基于事件之间的关联将新记忆连接到已有记忆之上)(Bartlett, 1995),各个记忆节点通过其时间关系以及因果常识关系(Hwang et al., 2021)进行连接。
在这种关联结构的支持下,在用于回复生成(RG)的记忆检索阶段(Phase II-1),我们超越了传统的 top-k 检索方法,进一步获取完整的“时间线”(timelines),从而避免遗漏那些与当前对话文本重叠较低但仍然重要的记忆(Tao et al., 2023)。最后,为了解决离线记忆构建与在线部署之间的不一致问题,THEANINE 在时间线检索后(Phase II-2)利用大语言模型对其进行基于当前对话的细化,使其能够为回复生成(Phase III)提供更加定制化的信息(Chae et al., 2023)。
本文的贡献主要体现在以下两个方面:
为实现终身对话智能体,本文提出了 THEANINE,这是一个基于大语言模型的框架,通过引入关系感知的记忆图结构以及“时间线增强”(timeline augmentation)机制来支持长期对话。实验结果表明,在自动评估、基于LLM的评估以及人工评估的回复生成(RG)任务中,THEANINE 均优于具有代表性的基线方法。同时,我们验证了该框架能够显著提升记忆检索质量,其处理流程也更符合人类偏好。据我们所知,这是首次在记忆管理与回复生成中显式建模“时间线”(即相互关联的相关记忆)的工作。
另一方面,由于对话与参考记忆之间缺乏“黄金映射”(golden mapping),使得评估基于记忆增强的智能体变得困难。为此,我们提出了 TeaFarm,一种基于反事实驱动的评估流程,用于在无需人工干预的情况下,衡量智能体在引用历史信息方面的表现。
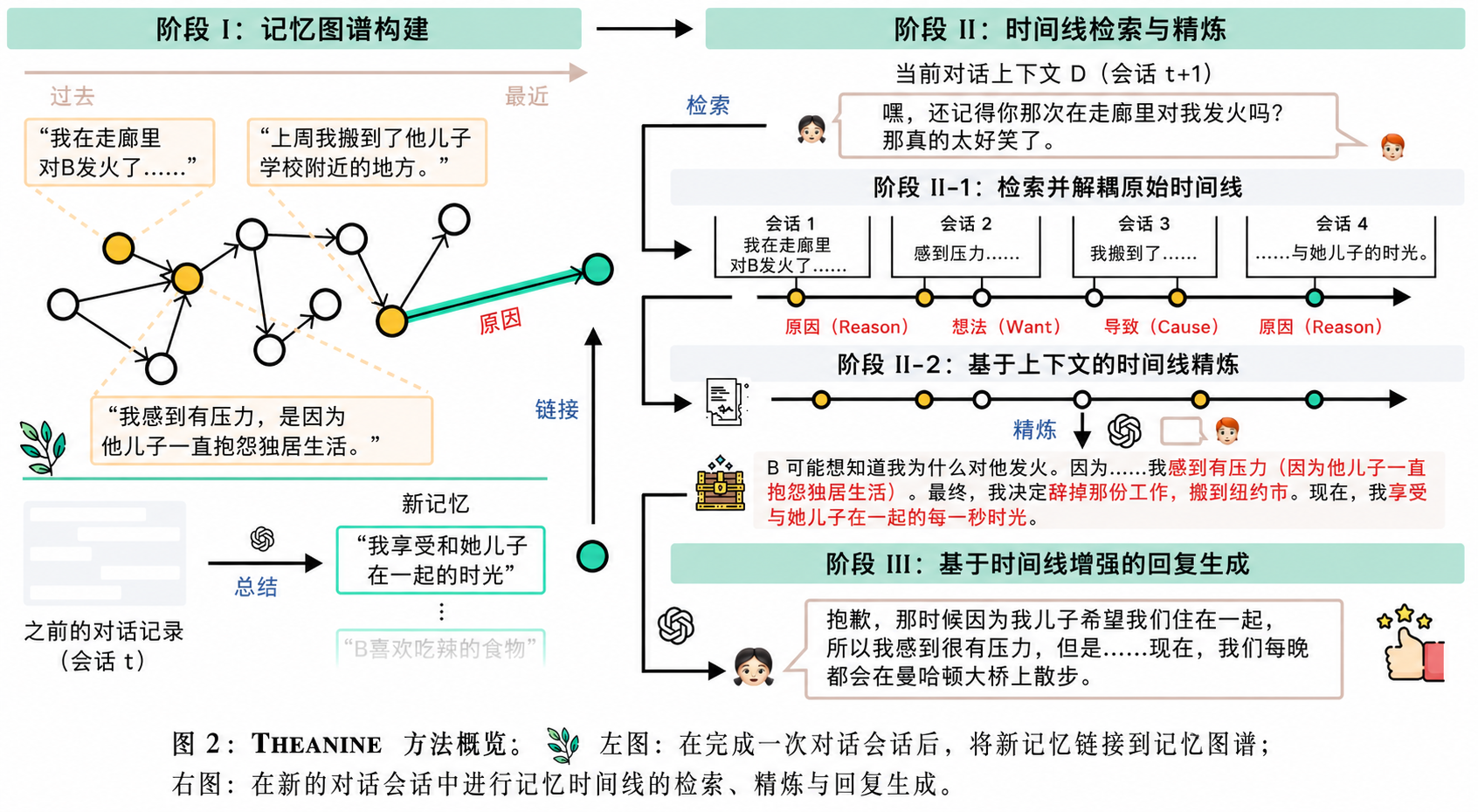
方法
我们提出 THEANINE,这是一个面向终身对话智能体的框架,其设计灵感来源于人类在对话过程中进行记忆存储与检索的方式(见图2)。
记忆图构建(Memory Graph Construction, Phase I)
为了管理大规模记忆,并为回复生成(RG)提供结构化信息(Mousavi et al., 2023;Chen et al., 2023),我们采用记忆图(memory graph)来建模记忆管理过程。该记忆图定义为:
$$
G = (V, E)
$$
其中:
$$
V = {m_1, m_2, …, m_{|V|}}
$$
$$
m = (event, time)
$$
$$
E = {\langle m_i, r_{ij}, m_j \rangle \mid m_i, m_j \in V \land r_{ij} \in R}
$$
$$
R = {Cause, Reason, Want, …, SameTopic}
$$
在图 $G$ 中,节点集合 $V$ 表示从对话中总结得到的记忆 $m$。每个记忆 $m = (event, time)$ 由一个事件(event)³以及其被形成(总结)的时间(time)构成。任意两个记忆节点之间的有向边 $e \in E$ 表示它们的时间顺序关系以及因果常识关系 $r \in R$。
在每个对话会话 $t$ 结束时,THEANINE 会将该会话中总结得到的新记忆 $m_{\text{new}}$ 逐一链接到当前的记忆图 $G_t$ 中,从而实现记忆的持续扩展与结构化组织。
Phase I-1:用于记忆链接的关联记忆识别(Identifying associative memories for memory linking)
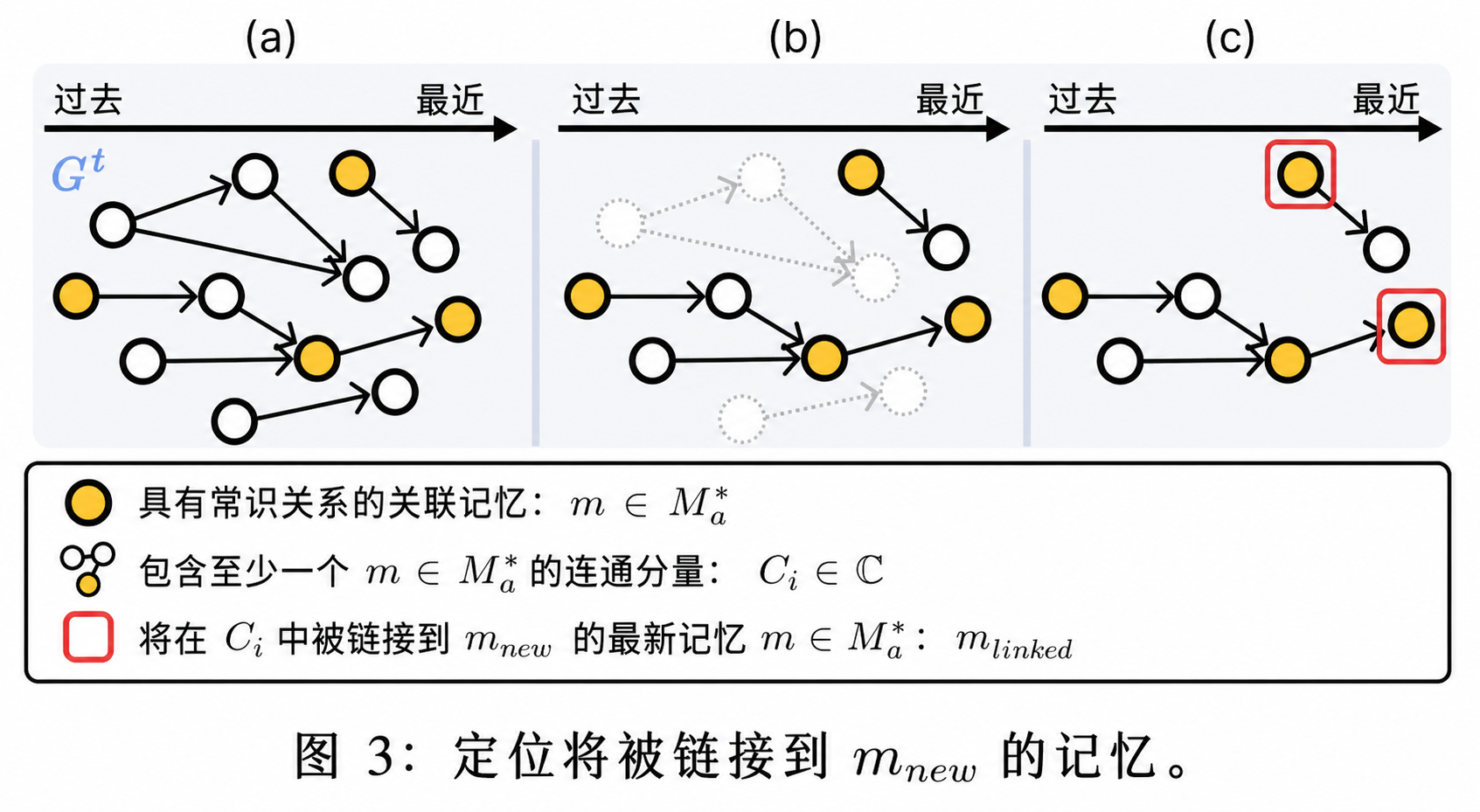
参考人类将新记忆与具有相似事件或主题的既有记忆进行关联的方式(即“关联记忆”,associative memories),THEANINE 首先从当前记忆图 $G_t$ 中识别这些关联记忆。
形式化地,给定一个待存储的新记忆 $m_{\text{new}}$,其关联记忆集合 $M_a$ 定义为在 $G_t$ 中与 $m_{\text{new}}$ 具有最高 $j$ 个文本相似度的记忆节点集合,即满足 $|M_a| = j$。
Phase I-2:关系感知的记忆链接(Relation-aware memory linking)
直观来看,我们可以通过边将 $m_{\text{new}}$ 与 $m \in M_a$ 连接起来,这些边仅表示它们之间的文本相似性以及时间先后顺序。然而,我们发现这种简化的连接方式(例如“这件事发生了 → 类似事件随后发生”)会导致图结构上下文信息不足,从而难以有效支持回复生成(详见第4节)。
相比之下,人类在理解事件时,往往会考虑事件之间的关系,例如“一个事件如何影响另一个事件?”或“为什么这个人会做出这样的改变?”。因此,THEANINE 采用了一种关系感知的记忆链接机制:在两个记忆之间建立边时,不仅编码它们的时间顺序,还引入其因果常识关系 $r \in R$。
在具体实现中,我们采用了 Hwang 等人(2021)提出的常用关系类型,包括 HinderedBy、Cause、Want 等在内的多种关系(详见附录 B.1)。
此外,在本文中,“事件”(event)指对话系统所感知的信息,包括说话者的行为或发言,以及对说话者人设(persona)的识别与确认。
接下来,我们首先确定 $m_{\text{new}}$ 与每个关联记忆之间的关系。形式化地,对于每一对 $m_{\text{new}}$ 和 $m \in M_a$,由大语言模型(LLM)基于它们的事件(event)、时间(time)以及其来源对话,分配一个关系 $r \in R$:
$$
M_a^* = { m_i \in M_a \mid \Upsilon(m_i, m_{\text{new}}) \in R }
$$
其中,$\Upsilon(\cdot, m_{\text{new}}) \in R$ 表示该记忆与 $m_{\text{new}}$ 之间被赋予了某种关系 $r \in R$,而所有被成功赋予关系的记忆集合定义为 $M_a^*$。
换言之,$M_a^*$ 表示那些不仅在文本上相关,而且在语义上(通过因果或常识关系)能够与新记忆建立有效连接的关联记忆子集。
随后,我们将 $m_{\text{new}}$ 连接到记忆图中。首先,我们定位所有包含至少一个 $m \in M_a^*$ 的连通子图(connected component)$C_i \subset G_t$,如图3(a)和(b)所示:
$$
C = { C_i \subset G_t \mid V(C_i) \cap M_a^* \neq \varnothing }
$$
其中,$C$ 表示满足条件的所有连通子图的集合,$V(\cdot)$ 表示“该子图中的节点集合”。
接着,对于每一个 $C_i \subset C$,我们将 $m_{\text{new}}$ 连接到其中最新的(most recent)$m \in M_a^*$(见图3(c))。与 $m_{\text{new}}$ 建立连接的记忆集合 $M_{\text{linked}}$ 定义为:
$$
M_{\text{linked}} = { \Omega\big(V(C_i) \cap M_a^*\big) \mid C_i \subset C }
$$
其中,$\Omega(\cdot)$ 表示“集合中时间上最新的记忆”。
这种策略确保在每个相关的连通子结构中,仅选择代表当前语境最新状态的记忆与 $m_{\text{new}}$ 建立连接,从而在控制图结构复杂度的同时,保留时间与语义上的关键演化信息。
在将会话 $t$ 中的所有记忆逐一链接到当前记忆图 $G_t$ 后,我们即可得到更新后的新记忆图 $G_{t+1}$。
Phase I 的整体流程(记忆图构建阶段)的伪代码如算法1所示。
时间线检索与时间线细化(Timeline Retrieval and Timeline Refinement, Phase II)
得益于所构建的记忆图结构,THEANINE 可以在回复生成(RG)过程中引入与当前对话相关的“事件时间线”(timelines),从而缓解传统记忆管理方式中的信息丢失问题(见图1)。在获得记忆图 $G_{t+1}$ 后,THEANINE 在会话 $t+1$ 的回复生成过程中执行以下步骤:
准备阶段:Top-k 记忆检索(Top-k memory retrieval)
在对话进行过程中,以当前对话上下文 $D = {u_i}_{i=1}^{n}$(由 $n$ 条话语 $u$ 构成)作为查询,从记忆图中检索出 top-$k$ 个最相关的记忆:
$$
M_{re} = \lbrace m_{re,i} \mid i = 1,\dots,k \rbrace
$$
这些检索到的记忆将作为后续时间线构建与细化的基础输入。
Phase II-1:原始记忆时间线的检索与解缠(Retrieving and untangling raw memory timelines)
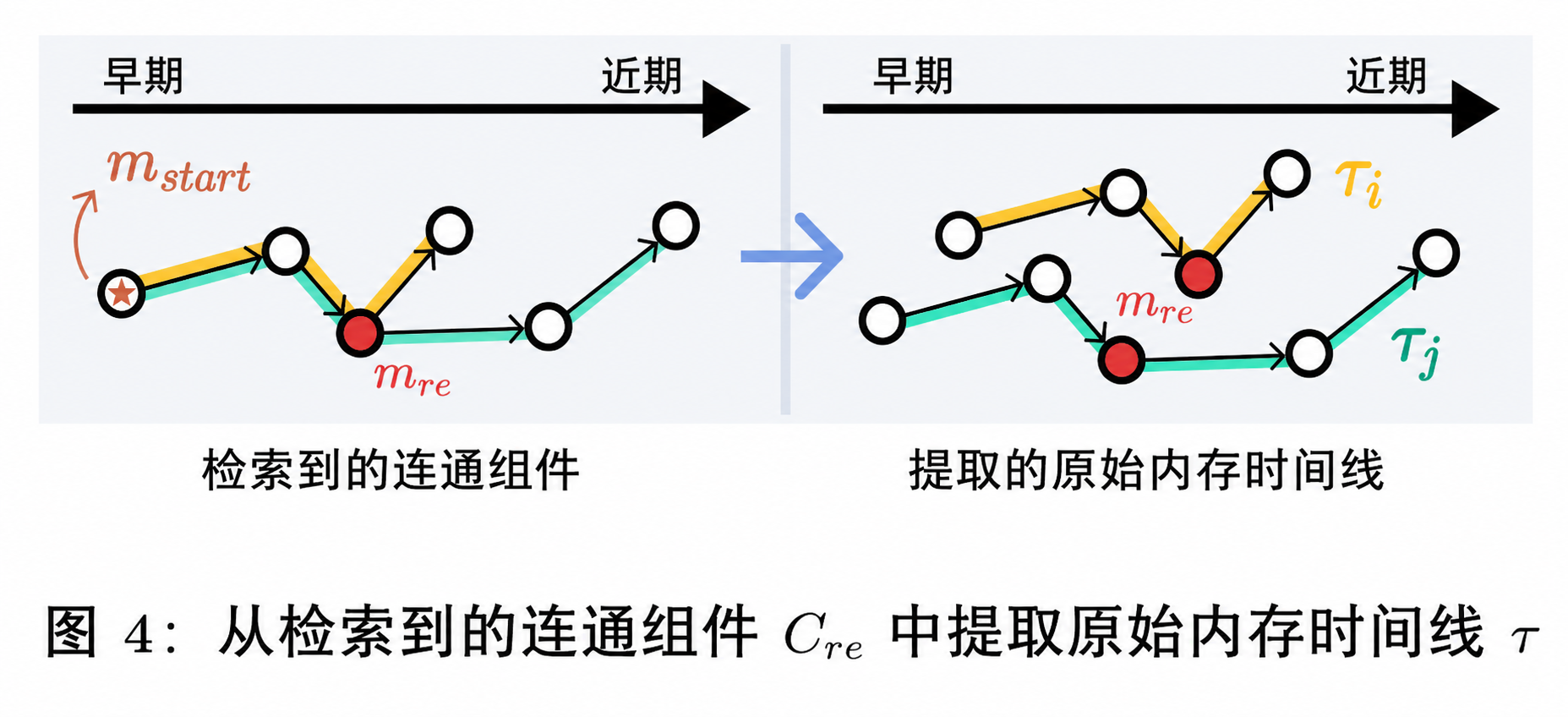
我们希望不仅获取 $M_{\text{re}}$ 中的记忆,还能够访问围绕这些记忆展开的相关上下文。形式化地,对于每个 $m_{\text{re}} \in M_{\text{re}}$,我们进一步基于记忆图中的连接结构,收集包含该节点的连通子图 $C_{\text{re}} \subset G_{t+1}$。
然而,由于图结构的存在,这些记忆集合(即 $C_{\text{re}}$)通常是“缠绕”的(即以复杂方式相互连接)。因此,我们需要将其“解缠”为若干条记忆时间线(memory timelines)。每一条时间线表示一系列围绕 $m_{\text{re}}$ 展开的事件,这些事件可能具有相似的起点,但在后续发展中分化为不同的路径。
为此,我们首先在 $C_{\text{re}}$ 中定位最早的记忆,作为所有时间线的起点 $m_{\text{start}}$(如图4左所示):
$$
m_{\text{start}} = \Theta\big(V(C_{\text{re}})\big)
$$
其中,$\Theta(\cdot)$ 表示“集合中时间最早的记忆”。
该起点为后续时间线的展开提供了统一的源头,使得不同事件发展路径可以在一致的时间基准下进行建模与分析。
接下来,以 $m_{\text{start}}$ 为起点,我们沿着时间的“未来方向”对记忆进行解缠,通过遍历图结构,从 $C_{\text{re}}$ 中提取所有包含 $m_{\text{re}}$ 的线性路径(如图4中所示的两条路径)。这一过程会持续进行,直到到达某个终止节点 $\tau[-1]$,其出度为 0(即 $\deg^{+}(\tau[-1]) = 0$,表示没有从该节点出发的有向边)。每一条这样的路径都被视为一条原始记忆时间线 $\tau$,用于刻画 $m_{\text{re}}$ 及其相关事件的一种演化过程:
$$
T = {\tau \subset C_{\text{re}} \mid \tau \text{ 是一条有向线性图,且 } m_{\text{start}}, m_{\text{re}} \in \tau \land \deg^{+}(\tau[-1]) = 0 }
$$
随后,我们从集合 $T$ 中采样 $n$ 条原始时间线 $\tau$。对所有检索得到的 top-$k$ 记忆重复执行 Phase II-1 后,我们最终获得一组原始记忆时间线集合:
$$
\mathcal{T} = \bigcup T, \quad |\mathcal{T}| = k \times n
$$
该过程使模型能够从图结构中提取出多条可能的事件发展路径,为后续更精细的时间线筛选与回复生成提供丰富的候选上下文。
Phase II-2:上下文感知的时间线细化(Context-aware timeline refinement)
尽管我们已经通过引入时间关系与常识关系构建了信息更丰富的记忆图,但如果直接将检索到的时间线用于回复生成(RG),效果仍可能不理想(见第4节 RQ3)。其原因在于:记忆图是在离线阶段构建的,并未考虑当前正在进行的对话上下文。因此,在本阶段中,THEANINE 通过“上下文感知的时间线细化”来弥合离线记忆构建与在线对话之间的差距。
受大语言模型能够对其生成结果进行自我优化与修正的能力启发(Madaan et al., 2024),我们利用 LLM 对原始时间线进行重构,使其转化为更契合当前对话需求的信息资源,例如去除冗余内容或突出关键信息。
形式化地,给定当前对话上下文 $D$ 和检索得到的原始时间线集合 $\mathcal{T}$,LLM 将每一条时间线 $\tau \in \mathcal{T}$ 转换为细化后的时间线集合 $\mathcal{T}_{\Phi}$:
\[ T_{\Phi} = \left\{ \arg\max_{\tau_{\Phi}} P_{\mathrm{LLM}}\left(\tau_{\Phi} \mid D, \tau\right) \mid \tau \in \mathcal{T} \right\} \]
最终,所有细化后的时间线 $\mathcal{T}_{\Phi}$ 将用于增强回复生成过程。
Phase II 的完整流程伪代码见算法2。
时间线增强的回复生成(Timeline-augmented Response Generation, Phase III)
在这一阶段,THEANINE 利用已经细化后的时间线来进行回复生成(RG)。
形式化地,给定当前对话上下文 \( D = \lbrace u_i \rbrace_{i=1}^{n} \) 以及细化后的时间线集合 \( \mathcal{T}_{\Phi} \), 大语言模型生成下一条回复 \( u_{n+1} \):
$$
u_{n+1} = \arg\max_{u_{n+1}} P_{\text{LLM}}(u_{n+1} \mid D, \mathcal{T}_{\Phi})
$$
也就是说,模型在生成回复时,不仅依赖当前对话内容 $D$,还融合了经过筛选与重构的历史事件时间线 $\mathcal{T}_{\Phi}$,从而能够更好地利用长期记忆中的关键上下文信息,提高回复的连贯性与一致性。
实验设置
数据集
目前,用于长周期、多会话对话的公开数据集仍然较为有限。首先,Multi-Session Chat(MSC)(Xu et al., 2022a)是在 PersonaChat(Zhang et al., 2018)的基础上构建的,通过将原始对话扩展为多轮(五个)会话来实现长期对话建模。随后,DuLeMon(Xu et al., 2022b)和 CareCall(Bae et al., 2022)相继被提出,分别面向中文和韩文的长期对话场景。
近年来,Conversation Chronicles(CC)(Jang et al., 2023)作为一个新的数据集被发布。与 MSC 不同,CC 为对话参与者引入了明确的关系设定,例如“员工与上司”等,从而增强了对话的结构性与语境约束。
除了这些开放域数据集之外,Psychological QA⁸ 则关注于临床场景下的长期对话(以中文为主)。在本文中,我们选择 MSC 和 CC 作为评估数据集,以聚焦英文对话场景;而多语言及特定领域的数据集(如 DuLeMon、CareCall 和 Psychological QA)则留待未来工作进一步探索。
基线方法(Baselines)
为了评估 THEANINE 的性能,除了一些直接利用全部历史对话或记忆的朴素基线方法之外,我们还引入了以下具有代表性的设置与方法:
Memory Retrieval(记忆检索)
遵循 Xu et al. (2022a) 的做法,我们使用检索器从记忆库中提取与当前对话上下文相关的记忆,以增强回复生成(RG)。
Memory Update(记忆更新)
在每个对话会话结束时,我们利用大语言模型实现 Bae et al. (2022) 提出的常用记忆更新算法。该算法包括多种操作,如 Change(修改)、Replace(替换)、Delete(删除)、Append(追加)等(详见附录 H)。
RSum-LLM
一种纯生成式方法(Wang et al., 2023),完全依赖 LLM,通过递归地对记忆池进行摘要与更新来生成回复,而不使用显式的检索模块。
MemoChat
由 Lu et al. (2023) 提出,该方法利用 LLM 的链式思维(Chain-of-Thought, CoT)能力:(i)以“主题—摘要—对话”的结构从历史对话中提取重要记忆;(ii)选择相关记忆;(iii)生成回复。
COMEDY
由 Chen et al. (2024b) 提出,该方法使用 LLM 对每个会话级别的记忆进行总结,并将其压缩为简短的事件表示、用户画像(如行为模式、情绪等)以及用户-智能体关系信息。随后,从这些压缩记忆中选择相关内容用于增强回复生成。
模型与实现细节(Models and Implementation Details)
大语言模型(Large language models)
在所有实验中(包括各类基线方法),我们统一采用 gpt-3.5-turbo-0125(OpenAI, 2023)用于:(i)记忆摘要(见表6)、(ii)记忆更新,以及(iii)回复生成。温度参数(temperature)设定为 0.75。
检索器(Retrievers)
对于涉及检索的设置,我们使用 text-embedding-3-small(OpenAI, 2024b)来计算文本相似度。在关联记忆识别(Phase I-1)和 top-$k$ 记忆检索(Phase II)中,我们将 $j$ 和 $k$ 均设为 3。而在“Memory Retrieval”基线方法中,按照 Xu et al. (2022a) 的设置,将 $k = 6$。
对话会话(Dialogue sessions)
在评估阶段,我们使用 MSC 和 CC 数据集的第 3 至第 5 个会话进行实验。这是因为在前两个会话(session 1–2)中,各方法表现几乎一致(由于尚未形成可更新的记忆)。
评估方案一:自动评估与人工评估(Evaluation Scheme 1: Automatic and Human Evaluations)
为了评估 THEANINE 在长期对话中的回复质量,我们遵循常见做法,采用三类评估方式:(i)自动评估(Automatic evaluations);(ii)G-Eval(Liu et al., 2023),一种基于大语言模型的生成评估框架;(iii)人工评估(human evaluation)。以下总结若干关键发现(具体细节、提示设计及评估界面见附录 E):
(发现1)THEANINE 在回复生成任务中优于各类基线方法。
| Methods / Metrics | MSC Bleu-4 | MSC Rouge-L | MSC Mauve | MSC BertScore | CC Bleu-4 | CC Rouge-L | CC Mauve | CC BertScore |
|---|---|---|---|---|---|---|---|---|
| All Dialogue History | 1.65 | 14.89 | 9.06 | 86.28 | 4.90 | 21.56 | 26.47 | 88.13 |
| All Memories & Current Context 𝒟 | 1.56 | 14.89 | 10.62 | 86.23 | 4.41 | 20.06 | 38.16 | 88.02 |
| + Memory Update (Bae et al., 2022) | 1.55 | 14.77 | 9.28 | 86.20 | 4.34 | 20.34 | 34.84 | 88.03 |
| Memory Retrieval (Xu et al., 2022a) | 1.92 | 15.49 | 11.16 | 86.47 | 4.93 | 20.63 | 33.06 | 88.07 |
| + Memory Update (Bae et al., 2022) | 1.67 | 15.30 | 13.71 | 86.39 | 4.46 | 20.19 | 34.28 | 88.02 |
| Rsum-LLM (Wang et al., 2023) | 0.75 | 11.53 | 2.45 | 84.91 | 0.98 | 11.42 | 2.28 | 85.59 |
| MemoChat (Lu et al., 2023) | 1.42 | 13.51 | 7.72 | 85.96 | 2.31 | 15.87 | 15.12 | 87.08 |
| COMEDY (Chen et al., 2024b) | 1.06 | 12.79 | 7.27 | 85.29 | 1.70 | 13.57 | 1.95 | 85.90 |
| THEANINE (Ours) | 1.80 | 15.37 | 18.62 | 86.70 | 6.85 | 22.68 | 64.41 | 88.58 |
表 1:回复质量的自动评估(各会话平均)
表1展示了不同方法在回复生成(RG)任务中的性能,评估指标包括基于重叠的指标和基于语义嵌入的指标,例如:
- Bleu-4(Papineni et al., 2002)
- Rouge-L(Lin, 2004)
- Mauve(Pillutla et al., 2021)
- BertScore(Zhang et al., 2020)
在两个数据集上,THEANINE 在整体回复质量方面均优于多种基线方法。尽管在 MSC 数据集上,相较于“Memory Retrieval”方法,THEANINE 在部分基于重叠的指标(如 Bleu-4 和 Rouge-L)上略低,但在基于语义表示的指标(如 Mauve 和 BertScore)上表现显著更优。
值得注意的是,包括 THEANINE 在内,不采用记忆更新机制的方法通常获得更高的评估分数。这一现象从实验层面支持了本文的核心观点:对于终身对话智能体而言,无需更新或删除记忆的管理策略更有利于提升整体性能。
(发现2 & 3)各阶段均对性能有贡献;整体检索“时间线”相比传统检索带来显著提升。
| Settings / Metrics | B-4 | R-L | Mauve | Bert |
|---|---|---|---|---|
| THEANINE (Ours) | 4.32 | 19.03 | 41.52 | 87.64 |
| w/o Relation-aware Linking | 4.07 | 18.58 | 39.69 | 87.57 |
| w/o Timeline Refinement | 4.03 | 18.82 | 41.34 | 87.66 |
| Broken Down, Shuffled Timeline | 4.15 | 18.70 | 38.49 | 87.61 |
| Memory Retrieval | 3.43 | 18.06 | 22.11 | 87.27 |
表 2:消融实验性能(各数据集平均)。
为了深入分析模型设计的有效性,我们进一步研究了以下因素对 THEANINE 性能的影响:
(i)在记忆链接阶段(Phase I-2)中移除“关系感知”(relation-awareness);
(ii)移除时间线细化(Phase II-2);
(iii)为客观评估“时间线整体检索”的作用,我们设计了一种对照设置:将检索到的时间线打散为随机排序的事件序列,使其在回复生成(RG)时与传统的 top-$k$ 检索格式一致。
从表2的结果可以观察到,各组件对性能的贡献排序为:
关系感知记忆链接 > 整体时间线检索 > 时间线细化
这一结果表明:
首先,引入因果关系的记忆图构建(relation-aware linking)对于提升性能最为关键,验证了在记忆结构中显式建模事件间因果关系的有效性。
其次,基于该图结构对相关事件进行“时间线级别”的整体检索,相比传统的 top-$k$ 检索方法,能够显著提升回复生成质量——即使初始检索规模更小($k=3$ 对比 $k=6$)。
最后,时间线细化(timeline refinement)虽然带来了性能提升,但增益相对较小,这表明其在实际应用于回复生成时仍存在优化空间,有待未来进一步研究。
(发现4)人工评估与 G-Eval 表明,THEANINE 在记忆检索的有效性与准确性方面均表现更优。
除了评估智能体生成的回复质量之外,我们还进一步分析了不同记忆构建方法对记忆检索质量的影响。在相同的当前对话作为查询条件下,图5展示了方法之间的两两对比(ours vs. baselines),评估其检索到的记忆在多大程度上有助于提升回复生成(RG)。
结果表明,THEANINE 在所有对比中均取得了更高的胜率,尤其是在人工评估中优势更为明显。这说明该方法能够为回复生成提供更有帮助的记忆增强信息。
除了“有用性”(helpfulness),对检索“准确性”(accuracy)的客观评估同样至关重要。然而,现有的长期对话数据集并未提供对话上下文与记忆之间的“黄金映射”(即标准答案)。为此,我们筛选了 50 个需要依赖历史记忆进行回复生成的对话上下文(测试样本),并对不同方法的检索准确率进行人工标注评估。
表3的结果显示,THEANINE 及其消融变体在检索准确率方面均优于各类基线方法,并且其性能排序与表1中的结果以及表4中的成功率保持一致。这进一步验证了该方法在记忆检索与利用方面的整体优势。
(发现5)人工评估表明,THEANINE 能生成更好地蕴含(entail)历史交互信息的回复。
在验证了 THEANINE 检索到的记忆具有较高“有用性”之后,我们进一步探究这些记忆是否能够促进可靠的长期人机交互。为此,我们组织标注人员通过多数投票的方式,对模型生成的回复进行判断:其与历史对话之间是“蕴含”(entail)、“矛盾”(contradict)还是“中立”(neutral)。
如图6所示,THEANINE 不仅将“矛盾”回复的比例降低至较低水平(4%),还在“蕴含”类别上取得了最高占比(68%)。这表明其生成的回复在很大程度上能够正确反映并延续历史对话内容,显著优于各类基线方法。
我们认为,这一优势源于其基于“时间线”的建模方式:通过组织相关记忆的演化过程,模型能够更好地刻画说话者之间的历史交互,从而生成与过去信息更加一致的回复。这种一致性对于对话智能体维持长期用户关系(例如建立亲密感)至关重要(Adiwardana et al., 2020)。
此外,这种高“蕴含性”与低“矛盾性”的特性也使 THEANINE 在特定应用场景中具有潜在价值。例如,在个性化医疗辅助等场景中,智能体需要确保其回复与用户历史信息(如电子健康记录或既往咨询记录)保持一致,这对于诊断决策具有重要意义(Tseng et al., 2024)。
补充说明:Memory Update 方法在“矛盾”回复方面表现更低(2%),这表明在以下两者之间可能存在权衡关系:(i)通过删除过时记忆来避免矛盾;(ii)保留这些记忆以为回复生成(RG)提供更丰富的信息(Kim et al., 2024a)。
(发现6)人工评估表明,THEANINE 的中间处理过程具有较高合理性。
如图7所示,评审人员在很大程度上认同 THEANINE 的中间步骤设计:
- 在记忆链接阶段,92% 的评审认为模型能够正确地为记忆之间分配因果关系,这也解释了其在性能上的提升;
- 在时间线细化阶段,评审一致认为(100%,共100个样本)该过程能够有效提取出更有助于回复生成的信息。
这些结果从人类评估角度进一步验证了 THEANINE 各个关键模块设计的有效性与合理性。更多关于各阶段处理过程及回复生成的具体示例见附录 G。
评估方案二:TeaFarm —— 基于反事实驱动的长期对话评估框架
(Evaluation Scheme 2: Counterfactual-driven Evaluation Pipeline)
在长期对话场景中,评估基于记忆增强的智能体具有较大挑战性,主要原因在于缺乏当前对话与“正确记忆”之间的标准映射(ground-truth mapping)。虽然可以借助 G-Eval,向评估用的 LLM(如 GPT-4)输入完整历史对话并判断回复是否正确引用过去信息,但这种方法的效果在很大程度上依赖于评估模型本身的能力(Kim et al., 2024b)。
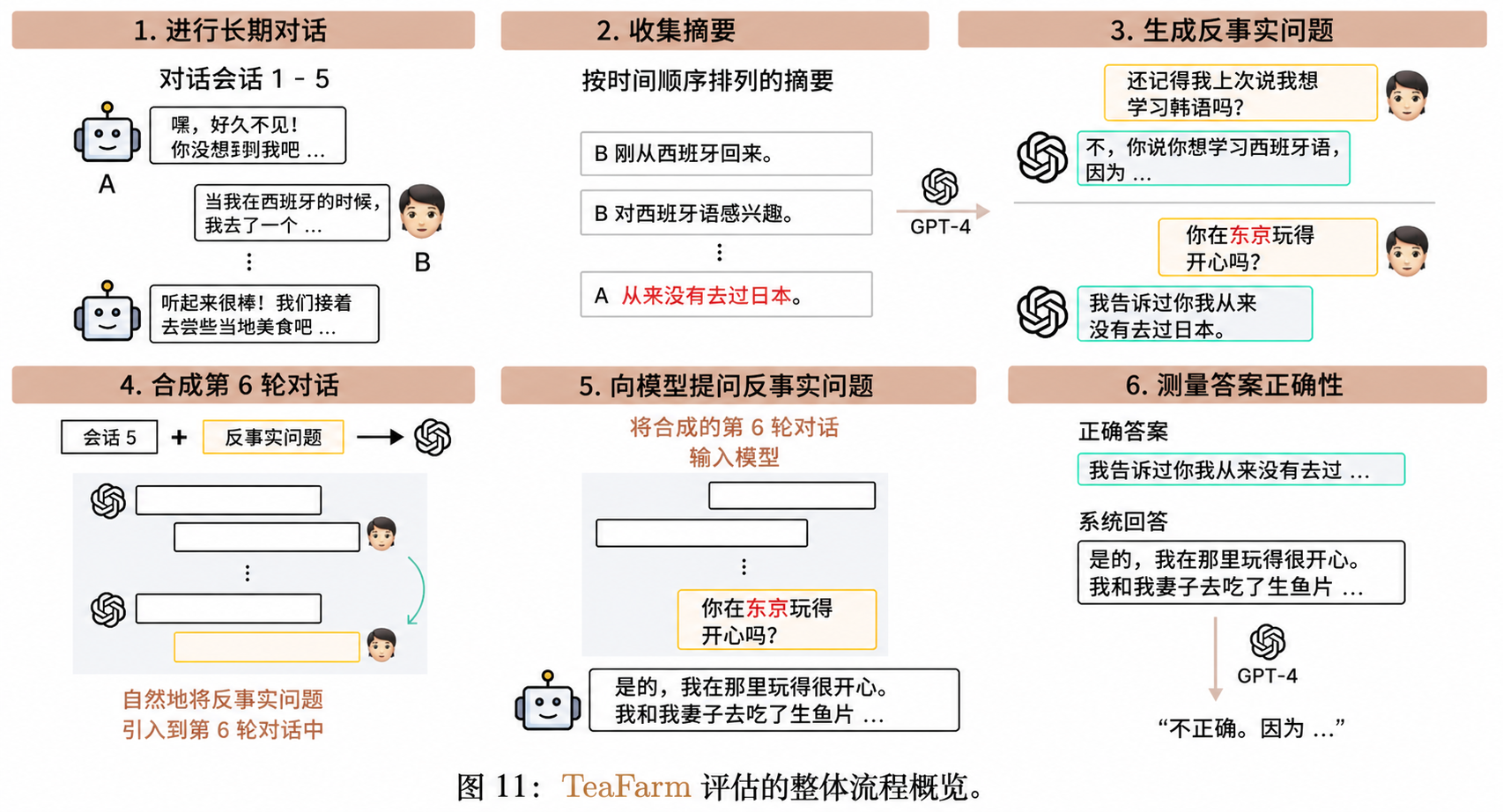
为了解决这一问题,本文在提出 THEANINE 的同时,引入了 TeaFarm ——一种无需人工参与的、基于反事实(counterfactual)驱动的评估流程,用于衡量长期对话中记忆增强回复生成的效果。
基于反事实问题的记忆能力测试
(Testing Dialogue Agents’ Memory via Counterfactual Questions)
在 TeaFarm 中,我们通过“误导”对话智能体来测试其记忆能力:系统会构造与事实相反的陈述(反事实),诱导模型生成错误回答,而只有正确引用历史对话信息的模型才能避免被误导。
具体而言,在与智能体对话时,我们会假装某些不真实的陈述为真(即反事实设定)。例如(见图8),问题可能基于错误前提提出,而模型需要识别并纠正这些前提。
在实践中,当评估一个已经与用户进行了多轮会话的智能体时,TeaFarm 的流程如下:
- 收集历史对话:整理所有过往会话,并按会话逐一进行摘要;
- 输入摘要:将这些按时间排序的摘要输入到问题生成 LLM,使其能够理解各事件的当前状态(例如:“说话者B没有车”);
- 生成反事实问题:从双方视角生成反事实问题及其正确答案;
- 模拟新会话:启动一个新的对话会话,与智能体进行自然交互;
- 提出问题:在对话过程中自然地引入反事实问题;
- 评估回答:根据模型是否能够抵抗误导、正确引用历史信息来评估其表现。
该方法的核心优势在于:无需人工标注“正确记忆”,即可通过反事实机制自动评估模型是否真正掌握并使用了历史信息。TeaFarm 的整体流程图、提示设计及合成数据示例分别见附录 C、H 和 D。
TeaFarm 评估结果(TeaFarm Results)
在表4中,THEANINE 在成功率(SR, Success Rate)上整体优于各类基线方法,尤其是在 Conversation Chronicles(CC)数据集上表现更为突出。消融实验的性能略低于完整模型,再次验证了关系感知记忆链接与时间线细化机制的有效性。
一个值得注意的现象是:所有方法的成功率整体较低。这表明 TeaFarm 作为评估框架具有较强的“压力测试”(stress-testing)能力,能够有效揭示长期对话中模型记忆能力的不足。
此外,一个有趣的发现是:采用检索机制的方法(与 THEANINE 类似)整体优于仅依赖 LLM 的方法(如 RSum-LLM、MemoChat 和 COMEDY)。这一结果在一定程度上支持了本文提出的观点——在大语言模型时代,构建结构化记忆管理机制(而非完全依赖生成能力)仍然至关重要。
最后,为了进一步分析模型的局限性,作者在附录 G 中提供了 THEANINE 在 TeaFarm 框架下失败案例的详细分析,以揭示对话智能体在某些复杂情境下仍面临的挑战。