摘要
大语言模型(LLMs)近年来已被广泛应用于对话智能体中。然而,用户与智能体之间不断延长的交互会累积大量对话记录,使得上下文窗口有限的 LLMs 难以维持连贯的长期对话记忆,也难以生成个性化回复。尽管检索增强记忆系统已被提出以缓解这一问题,现有方法通常依赖单一粒度的记忆划分与检索。这种方式难以捕捉深层次的记忆关联,往往只能检索到部分有用信息,或引入大量噪声,从而导致性能不佳。为解决这些局限,本文提出了 MemGAS,一个通过构建多粒度关联、自适应选择与检索来增强记忆整合能力的框架。MemGAS 基于多粒度记忆单元,并采用高斯混合模型(Gaussian Mixture Models)将新记忆与历史记忆进行聚类与关联。基于熵的路由器通过评估查询相关性分布,自适应地选择最优粒度,在信息完整性与噪声之间取得平衡。检索到的记忆还会通过基于 LLM 的过滤进一步精炼。四个长期记忆基准上的实验表明,MemGAS 在问答任务和检索任务上均优于当前最先进方法,并在不同查询类型和不同 top-K 设置下取得了更优表现1。
引言
近年来,大语言模型(LLMs)已被广泛应用于对话代理中。然而,随着用户与代理之间的交互不断延长,所积累的大量对话记录使得上下文窗口受限的LLMs难以维持连贯的长期对话记忆,也难以提供个性化的响应。尽管基于检索增强的记忆系统已被提出以缓解这一问题,但现有方法通常依赖于单一粒度的记忆划分与检索。这种方式难以捕捉深层次的记忆关联,往往导致有用信息的部分缺失或引入大量噪声,从而影响整体性能。
为了解决上述局限,本文提出了 MemGAS 框架,通过构建多粒度关联、自适应选择与检索机制来增强记忆整合能力。MemGAS 基于多粒度记忆单元,利用 高斯混合模型(Gaussian Mixture Models) 对新记忆进行聚类,并将其与历史记忆建立关联。同时,引入基于熵的路由机制(entropy-based router),通过评估查询相关性分布,自适应选择最优粒度,在信息完整性与噪声之间取得平衡。检索到的记忆还会通过基于LLM的过滤进一步优化。
在四个长期记忆基准数据集上的实验结果表明,MemGAS 在问答任务和检索任务中均优于当前最先进方法,在不同查询类型和不同 top-K 设置下都表现出更优的性能。
近期关于LLM智能体外部记忆系统的研究,主要依赖于检索增强生成(Retrieval-Augmented Generation, RAG)范式,并从记忆划分与构建等多个方面探索如何实现高效检索。在记忆划分方面,现有方法主要采用单一粒度(single-granularity)对对话进行分割。一类方法使用会话级片段(session-level chunks)作为检索单元,而另一类方法则采用更细粒度的轮次级划分以捕捉更丰富的细节信息。近期的进展引入了基于主题感知(topic-aware)的划分技术,通过语义一致性对对话进行分组,从而提升围绕主题的一致性检索能力。
此外,一些研究通过生成记忆摘要,将关键信息压缩为紧凑表示,以提高检索效率。在记忆构建方面,研究者探索了多种结构化组织范式,以增强长期知识的保留能力。例如,RAPTOR(Sarthi et al., 2024)和 MemTree(Rezazadeh et al., 2024)采用树结构来编码记忆单元之间的多尺度关系。一些工作提出了层级化记忆架构(hierarchical memory architectures),构建具备深层抽象能力的复杂系统,从而支持高效的自顶向下检索。还有研究采用基于图的记忆架构,以模拟神经记忆巩固过程,并显式建模实体之间的关系结构。
然而,尽管现有方法取得了一定进展,但仍然存在两个关键局限:
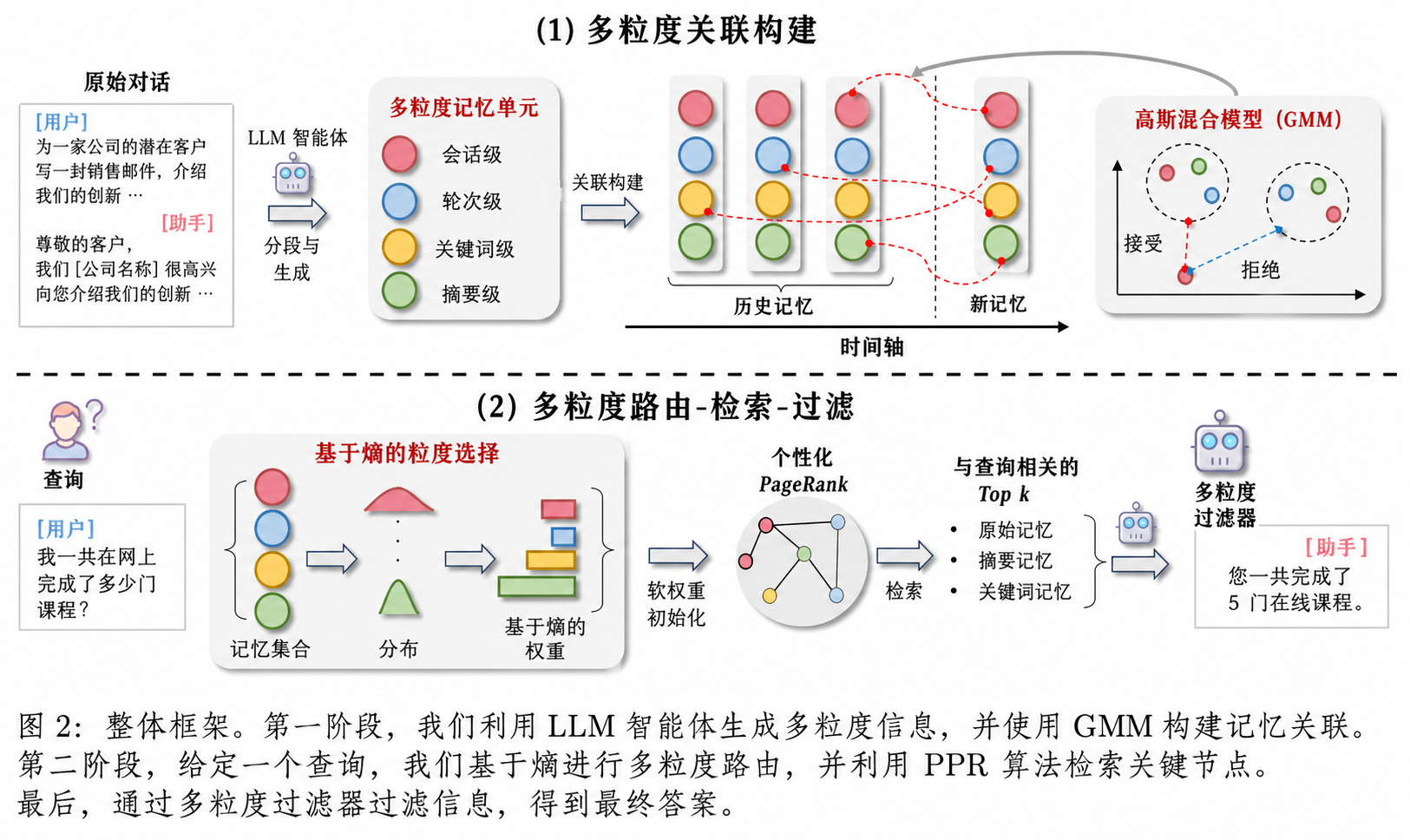
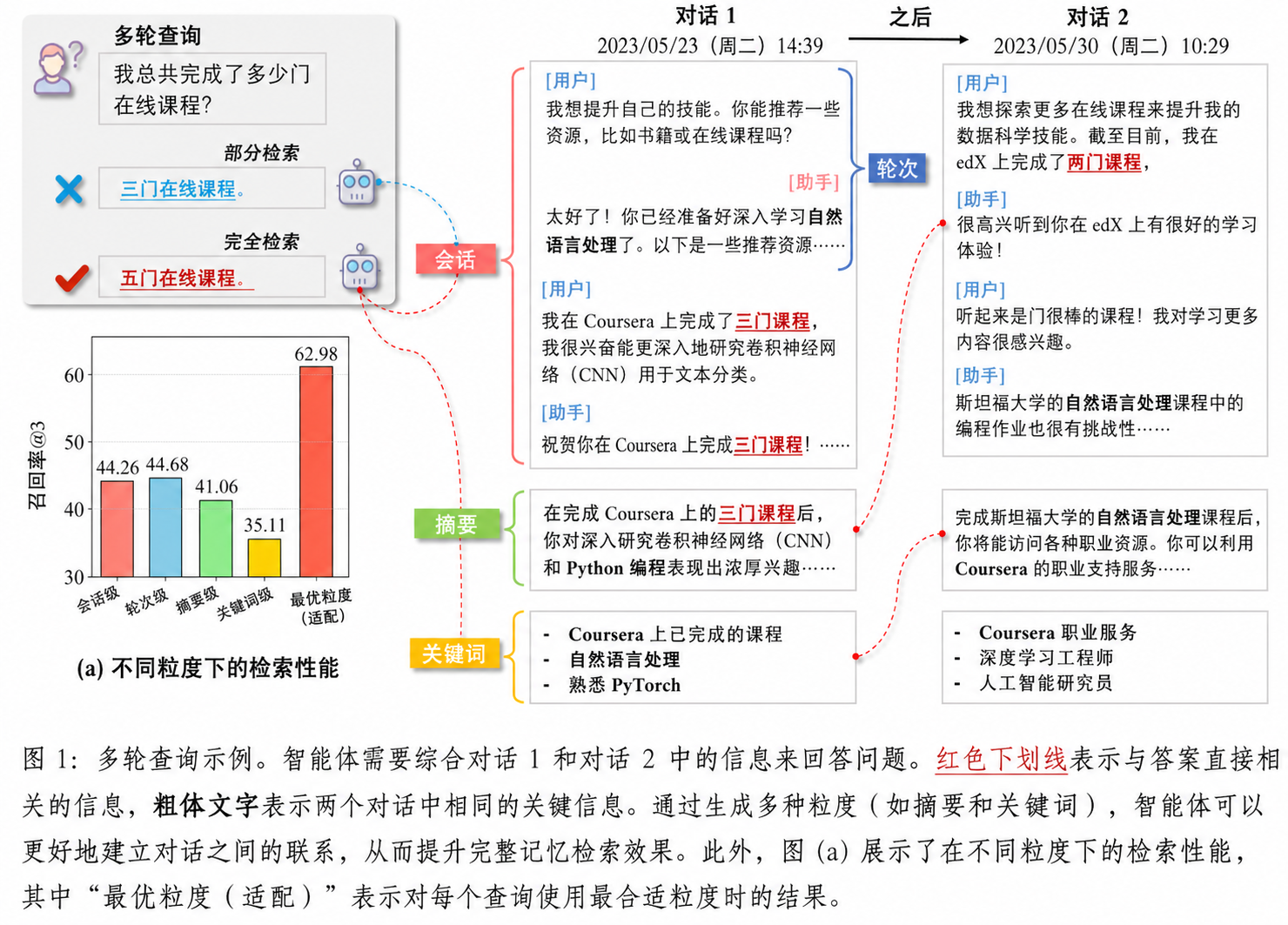
(i)多粒度记忆连接不足。 虽然已有研究尝试将记忆组织为拓扑结构(例如知识图谱或树结构),但这些方法大多聚焦于单一粒度层级——要么是实体级别,要么是会话摘要级别。这种单尺度范式无法建模不同粒度记忆单元之间的跨层交互,导致检索结果往往只包含部分有用信息。如图1所示,在回答跨多轮会话的问题时,需要在不同粒度之间建立语义关联(例如通过共享关键词或摘要将对话1与对话2连接起来)。如果未能建立这种关联,就会出现信息检索不完整的情况(例如仅检索到对话1),从而导致错误答案。
(ii)缺乏自适应的多粒度记忆选择机制。 当前方法主要依赖固定的粒度策略(如基于会话或轮次的划分,或由LLM生成的摘要),这往往由于粒度选择不当而导致上下文信息缺失或噪声干扰。尽管基于主题的划分方法能够提升片段内部的一致性,但它们缺乏针对不同查询动态选择粒度的能力。我们在图1(a)中的实证分析表明,根据每个查询自适应地选择最合适的粒度(例如在摘要/关键词带来的降噪效果与原始会话的信息完整性之间进行权衡)可以显著提升性能。这一发现凸显了粒度选择在解决“信息-噪声权衡”问题中的重要性。
基于上述问题,本文提出了 MemGAS 框架,通过多粒度关联与自适应选择来构建和检索长期记忆。我们的方法主要包含两个核心策略:
(i)记忆关联(Memory Association): 利用LLMs生成记忆摘要和关键词,构建多粒度记忆单元。在新记忆更新时,采用高斯混合模型(Gaussian Mixture Model)将历史记忆划分为接受集合(相关)与拒绝集合(不相关),并将接受集合中的记忆与新记忆建立关联,从而实现记忆结构的整合与实时更新。
(ii)粒度选择(Granularity Selection): 引入基于熵的路由机制,通过评估查询相关性分布的不确定性,自适应地为不同粒度分配检索权重。随后,利用个性化PageRank算法检索关键记忆,并通过LLM进行过滤以去除冗余信息,从而获得高质量、精炼的记忆内容,提升对话系统的理解能力。
在四个开源长期记忆基准数据集上的实验表明,MemGAS 在问答任务和检索任务上均显著优于当前最先进方法以及单一粒度方法,并在不同查询类型及不同 top-k 设置下持续取得更优表现。
方法
本节首先对任务与数据格式进行定义,随后构建一个动态记忆关联框架,详细介绍一种基于熵的路由机制以选择更合适的粒度,并概述用于检索与过滤高质量上下文信息以生成响应的策略。
预备知识(Preliminary)
本文的研究重点在于通过长期对话记忆构建个性化助手。在该设定下,系统利用跨多个会话的用户—代理交互(统称为“记忆”)来构建外部记忆库 $M$。不失一般性地,第 $i$ 个会话可表示为
\[ S_i = \{(u^{(i)}_j, a^{(i)}_j)\}_{j=1}^{n_i} \]
其中包含 $n_i$ 轮对话,每一轮由用户输入 $u^{(i)}_j$ 和助手回复 $a^{(i)}_j$ 组成。当助手接收到查询 $q$ 时,我们的目标是通过跨多粒度(包括会话级 $S$、轮次级 $T$、关键词级 $K$ 和摘要级 $U$)的关联机制,从记忆库 $M$ 中检索出相关记忆子集 $M_{\text{rel}} \subseteq M$,并基于这些信息生成响应:
\[ a = \text{LLM}(q, M_{\text{rel}}) \]
该问题的核心挑战在于:一方面,需要建立跨不同粒度的记忆关联;另一方面,需要学习一种自适应的粒度选择函数
\[ \psi: q \rightarrow {\alpha_s, \alpha_t, \alpha_k, \alpha_u} \]
以在信息完整性与检索噪声之间实现有效平衡。多粒度关联构建(Multi-Granularity Association Construction)
现有方法通常将记忆编码为向量库(例如基于会话级的片段),并通过相似度搜索直接进行信息检索。然而,这类方法忽视了记忆之间更深层次的关联关系。为了解决这一问题,本文提出了一种关联式记忆构建过程,用于捕捉多粒度之间的关系。
多粒度记忆元数据(Multi-Granular Memory Metadata)。 对于第 $i$ 个会话 $S_i$,利用LLM生成多粒度的元数据,包括会话摘要 $U_i$ 和关键词 $K_i$。同时,将该会话划分为多个对话轮次 $T_i$。形式化表示为:
\[ U_i, K_i = f_{\text{LLM}}(S_i), \quad T_i = \text{segment}(S_i) \]
其中,$f_{\text{LLM}}$ 表示 LLM 处理函数,$\text{segment}$ 表示分割操作。最终得到的记忆单元 $M_i$ 融合了会话级信息 $S_i$、轮次级对话 $T_i$、摘要 $U_i$ 以及关键词 $K_i$,并存储于记忆库中:
\[ M_i = \{S_i, T_i, U_i, K_i\} \in M \]
动态记忆关联(Dynamical Memory Association)。 当新增记忆 $M_{\text{new}}$ 被加入时,当前记忆库 $M_{\text{cur}}$ 会更新为:
\[ M_{\text{cur}} \leftarrow M_{\text{cur}} \cup M_{\text{new}} \]
为了在新记忆与历史记忆之间建立关联,本文采用基于 高斯混合模型(Gaussian Mixture Model, GMM) 的聚类策略。具体而言,记忆库中每个元素的不同粒度都会被编码为稠密向量表示。对于会话级、轮次级、摘要级和关键词级元数据,分别表示为 $e(S_i)$、$e(T_i)$、$e(U_i)$ 和 $e(K_i)$。因此,整个记忆库 $M_{\text{cur}}$ 可以表示为由这些多粒度向量组成的集合。
随后,在新记忆 $e(M_{\text{new}})$ 与当前记忆库 $e(M_{\text{cur}})$ 之间计算两两相似度分数,覆盖每个记忆的所有粒度。得到的相似度向量集合 $s_{\text{sim}}$ 会通过 GMM 进行聚类,并划分为两个概率集合:
- 接受集合(Accept Set): 与 $M_{\text{new}}$ 相似度较高的记忆,与新记忆建立直接关联;
- 拒绝集合(Reject Set): 与新记忆无关的记忆,在当前阶段不建立连接。
需要注意的是,相似度向量是在**粒度特定信息(granularity-specific information)**的基础上计算的,这意味着 $M_{\text{new}}$ 的每一种粒度都被视为一个节点,并用于与 $M_{\text{cur}}$ 中的节点建立连接。我们维护一个关联图 $A_{\text{cur}}$ 来存储记忆库 $M$ 中的这些连接关系,其更新方式为:
\[ A_{\text{cur}} \leftarrow A_{\text{cur}} \cup A_{\text{new}} \]
其中 $A_{\text{new}}$ 表示 $M_{\text{new}}$ 与其接受集合之间所形成的边。该过程通过有选择地强化在上下文上相关的记忆,模拟了类似人类的记忆巩固机制。
多粒度路由器(Multi-Granularity Router)
现有方法通常依赖单一预定义的粒度进行记忆检索,这限制了其根据查询内容自适应地优先选择细粒度或粗粒度信息的能力。为了解决这一问题,本文提出了一种基于熵的路由机制(entropy-based router),能够针对每个查询动态选择最合适的粒度。
基于熵的粒度选择(Entropy-Driven Granularity Selection)。 对于给定查询 $q$,首先计算其与各个粒度层级 $g \in {\text{session}, \text{turn}, \text{summary}, \text{keyword}}$ 上所有记忆片段之间的相似度。设:
\[ s_g = [\text{sim}(q, M^g_1), \dots, \text{sim}(q, M^g_n)] \]
表示查询 $q$ 与粒度 $g$ 下 $n$ 个记忆片段之间的相似度分数。随后,将 $s_g$ 归一化为概率分布 $p_g(s_g)$,并计算其香农熵(Shannon entropy):
\[ H^g = - \sum_{i=1}^{n} p_i^g(s^g)\,\log p_i^g(s^g), \quad \text{where } p_i^g(s^g) = \frac{\exp\big(\operatorname{sim}(q, M_i^g)/\lambda\big)} {\sum_{j=1}^{n} \exp\big(\operatorname{sim}(q, M_j^g)/\lambda\big)}, \ \forall i \in \{1, \ldots, n\}. \]
其中,$H_g$ 用于量化查询 $q$ 在粒度 $g$ 下与记忆匹配的不确定性程度。参数 $\lambda$ 是用于控制熵影响程度的超参数,其具体作用与设置在附录 F 中进行了分析。
软路由权重(Soft Router Weights)。 我们的核心动机在于:较低的熵 $H_g$ 通常意味着更高的匹配置信度(例如,较低的不确定性表明查询与某些记忆之间存在明确对应关系);相反,较高的熵则意味着匹配更加模糊(即难以确定查询对应的具体记忆)。为刻画这一特性,我们通过对熵的倒数进行归一化来为不同粒度分配权重:
\[ w_g = \frac{1/H_g}{\sum_{g'=1}^{G} 1/H_{g'}} \]
其中,$G$ 表示粒度的总数。该公式保证了熵较低(确定性更高)的粒度会被赋予更大的权重。因此,在检索过程中,系统会对与查询最具确定性关联的粒度所对应的记忆进行强化,从而无需人工干预即可实现自适应优化。
关于多粒度关联与路由机制的理论分析,详见附录 H。
记忆检索与过滤(Memory Retrieval and Filter)
在完成多粒度记忆关联构建并确定粒度权重之后,我们基于图结构化记忆 ${M_i, A_i} \in M \times A$ 对查询 $q$ 进行相关记忆检索。为充分利用记忆之间的关系,本文采用**个性化PageRank(Personalized PageRank, PPR)**算法进行上下文感知排序。
在粒度层面上,我们将每个 $M_i^g$(即记忆 $M_i$ 在第 $g$ 个粒度上的节点)视为关联图中的一个独立节点。对于每个粒度 $g$,首先根据公式(4)中路由器分配的权重 $w_g$,计算节点 $M_i^g$ 的初始相关性得分:
\[ \text{score}_i^g = w_g \cdot \text{sim}(q, M_i^g) \]
其中,$\text{sim}(q, M_i^g)$ 表示查询嵌入 $e(q)$ 与该粒度下记忆嵌入 $e(M_i^g)$ 之间的余弦相似度。所有得分集合 ${\text{score}_i^g}$ 构成了粒度级节点上的个性化初始概率分布。
随后,我们选取得分最高的前 $\alpha$ 个节点作为种子节点(具体分析见附录 F),并在多粒度关联图上运行PPR算法,使相关性沿图结构传播,从而突出那些既与查询直接相关、又与其他高价值节点紧密连接的节点。算法收敛后,根据最终的PPR得分选取得分最高的前 $k$ 个节点,作为候选上下文。参数 $k$ 的影响在第3.4节中进行了实证分析。
基于LLM的冗余过滤(LLM-Based Redundancy Filtering)。 为减少噪声并消除多粒度记忆中的冗余信息,我们引入基于LLM的过滤机制。该机制将检索得到的前 $K$ 条记忆与查询 $q$ 一同输入,通过精心设计的提示词(见附录 J),识别并剔除无关或重复内容。最终提供给响应生成模块的上下文被精炼为仅包含与查询最相关的关键信息,从而生成更加简洁且个性化的回复。
关于多粒度信息的案例分析见附录 K.2,过滤机制的案例分析见附录 K.3。
实验(Experiments)
实验设置(Experimental Settings)
数据集与评估指标(Dataset and Metrics)。 本文在四个综合性的长期记忆数据集上开展实验:LoCoMo、Long-MT-Bench+、LongMemEval-s 和 LongMemEval-m,这些数据集均用于评估LLM智能体在长期对话场景下的能力。由于本文的方法不涉及训练过程(training-free),因此数据集中的全部问答对均用于评估。更详细的数据集统计信息见附录 A。
为了全面评估模型性能,本文采用多种评价指标,包括:F1 分数(参考 Maharana 等人的设置)、BLEU(默认使用4-gram)、BERTScore,以及 ROUGE 分数(参考 Pan 等人的设置)。此外,本文还引入 GPT4o-as-Judge(GPT4o-J) 作为评估方式,即利用 GPT4o 来评估模型生成回答与参考答案之间的一致性。具体的评估提示词详见附录 J。
基线方法(Baselines)。 我们将 MemGAS 与多种方法进行了对比:
(1)Full History:直接利用最新的全部对话记录,最多包含 128k tokens 的上下文;
两种强大的检索模型:
(2)MPNet,
(3)Contriever;
四种基于记忆的对话模型:
(4)RecurSum:通过LLM递归生成和更新记忆摘要,以支持上下文相关的响应;
(5)MPC:结合提示工程与外部记忆增强LLM能力;
(6)A-Mem:通过生成笔记与链接结构来组织记忆;
(7)SeCom:将记忆划分为语义一致的主题块,并通过压缩去噪提升检索效果;
两种结构化RAG模型:
(8)HippoRAG 2:引入知识图谱以提升检索效率;
(9)RAPTOR:通过递归摘要与层级聚类构建树结构以增强检索能力;
此外,还包括两种近期提出的记忆模型:
HMEM:提出四层层级化记忆结构,并结合位置索引机制;
COMEDY:提供统一的“One-for-All”压缩记忆框架,无需传统记忆存储结构。
由于篇幅限制,HMEM 与 COMEDY 的实验结果见附录 I.2,更多细节见附录 B。
实现细节(Implementation Details)。 我们在所有任务中均使用 gpt-4o-mini-2024-07-18 作为基础模型,包括多粒度信息生成与问答任务。为保证公平性,所有基线方法均采用一致的生成提示。LLM 的 temperature 设置为 0 以确保结果可复现,所有模型均在 zero-shot 设置下运行,具体提示模板见附录 J。
在检索设置上,所有模型统一采用 top-3 会话检索策略;对于 SeCom 使用 top-3 片段,对于 RAPTOR 使用会话或摘要。编码模型统一采用 Contriever 来生成记忆文本的向量表示。超参数通过网格搜索确定:$\lambda \in {0.1, 0.2, 0.3, 0.5, 0.7, 1.0}$,$\alpha \in {5, 10, 15, 20, 25}$。
由于 LongMTBench+ 缺乏检索任务的真实标注,因此不纳入检索评估。此外,RAPTOR 与 A-Mem 无法在会话级 Recall 指标下进行评估,因为其存储单元为抽象或重写后的表示,无法与真实会话建立确定映射。在 LongMemEval-m 数据集上,RAPTOR、A-Mem 和 HippoRAG 的结果由于运行成本较高而未提供。
我们还在不同检索器、生成器及查询类型下对多种方法进行了对比分析(详见附录 E.1、E.2 和 E.3)。此外,附录 F 提供了超参数分析,附录 G 提供了误差分析,附录 D 则讨论了方法的额外开销与效率表现。
整体结果(Overall Results)
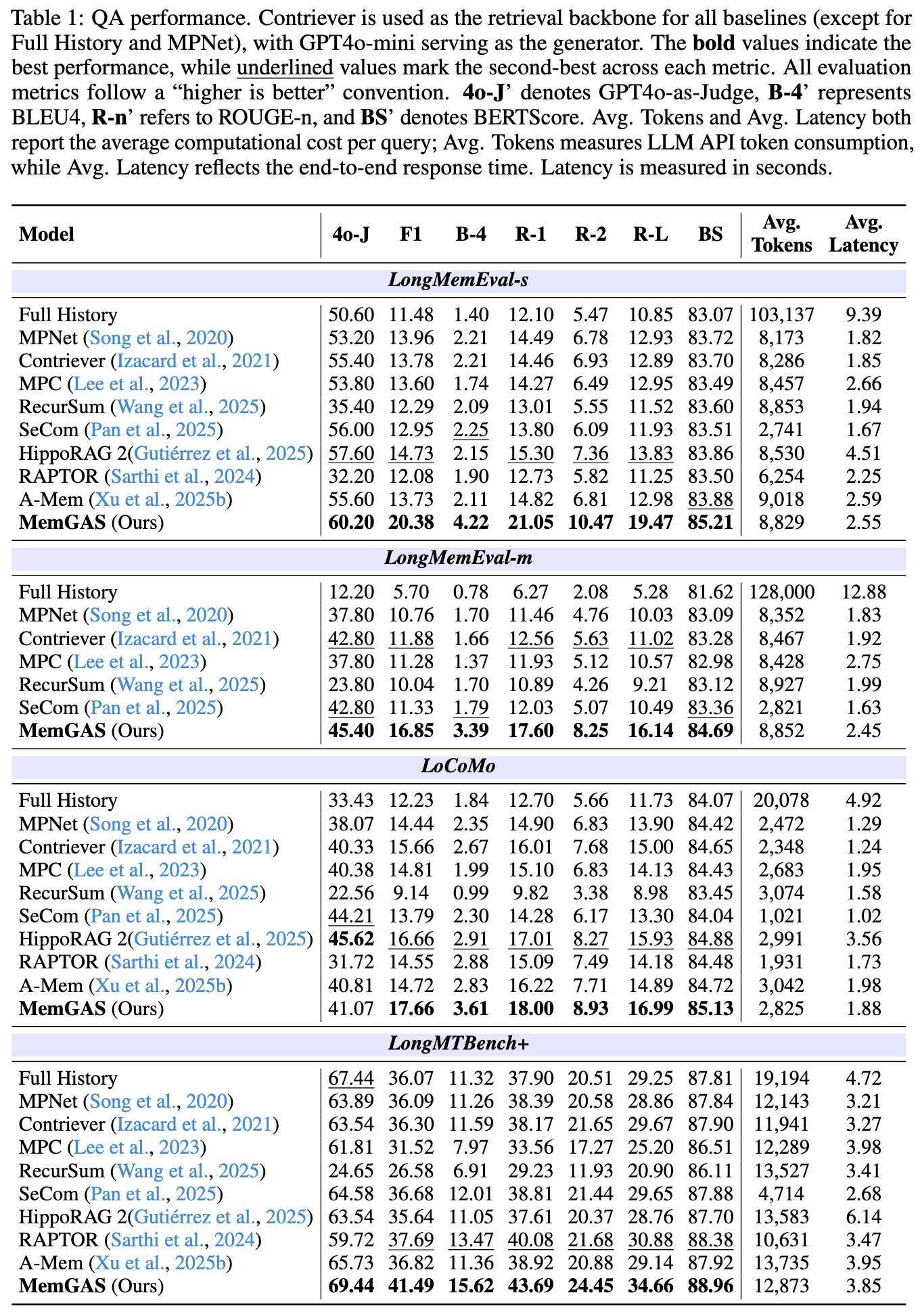
我们分别在表1和表2中展示了问答任务(Question Answering)和检索任务(Retrieval)的实验结果。此外,单一粒度与多粒度方法的对比结果见附录 C。下面对主要结果进行分析。
问答结果(Question Answering Results)。 如表1所示,MemGAS 在大多数数据集和评估指标上均稳定优于其他方法。与使用全部历史上下文、容易引入噪声的 Full History 方法不同,MemGAS 通过有效整合并检索最相关的记忆,实现了更优性能。其他基线方法(如 RecurSum 和 SeCom)虽然在特定粒度上进行建模,但由于缺乏跨粒度记忆关联能力,整体效果仍不理想。
此外,HippoRAG 2 和 RAPTOR 等方法虽然能够在记忆单元之间建立一定的连接,但未能有效构建多粒度关系及其选择机制,从而限制了性能表现。相比之下,MemGAS 通过多粒度记忆单元的动态构建、自适应路由机制以及冗余过滤策略,实现了更优表现,突出了“关联”和“选择”在记忆管理中的关键作用。
在效率方面,MemGAS 在保持具有竞争力的 token 使用量的同时,实现了更高质量的问答表现,并且相较于 A-Mem 和 RecurSum 等方法,其延迟相当甚至更低,使其在准确性与效率之间取得了更优平衡。
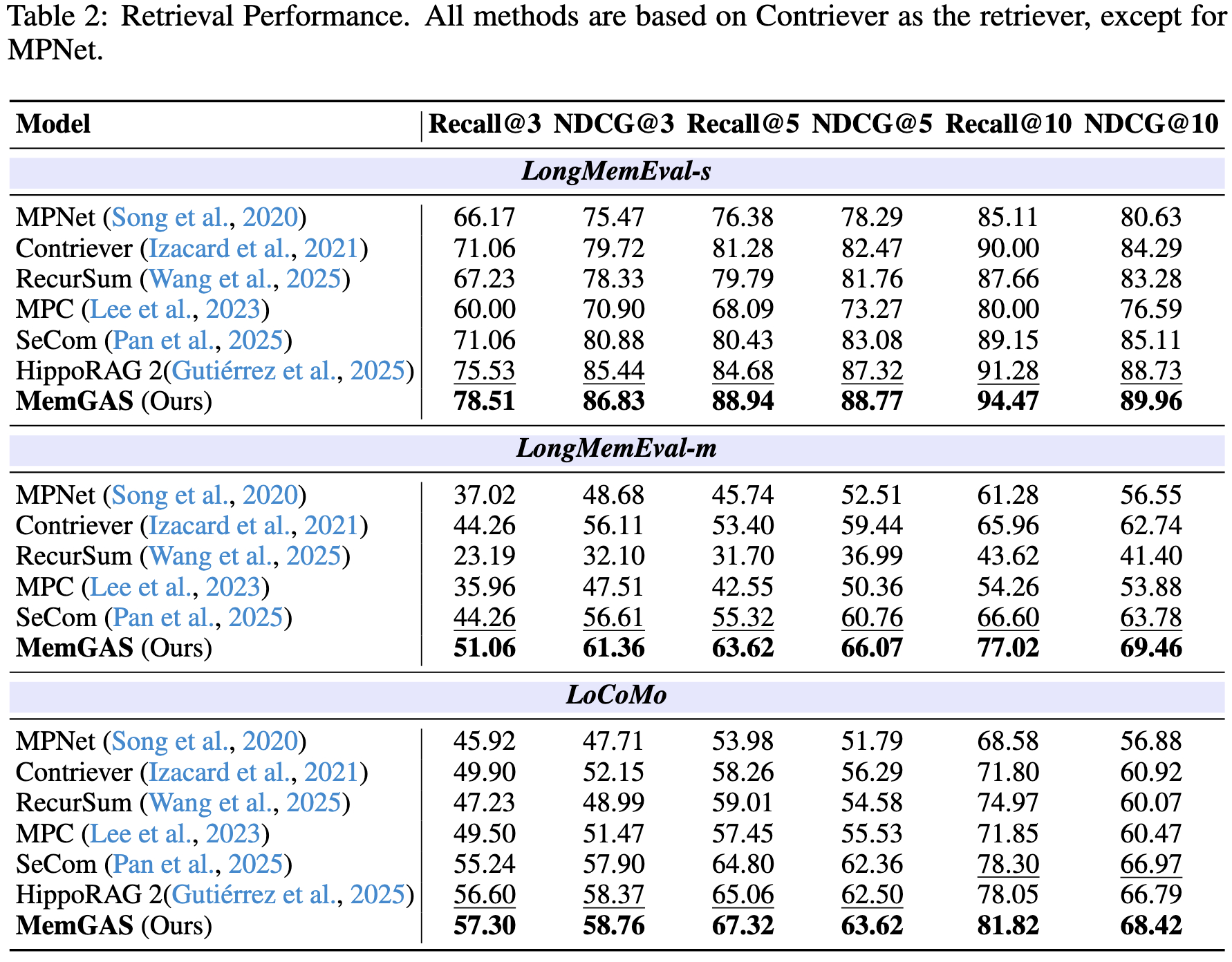
检索结果(Retrieval Results)。 如表2所示,MemGAS 在所有数据集上均表现出色,在 Recall 和 NDCG 等指标上持续取得最佳成绩。这些结果表明,该方法在长期记忆构建与检索方面具有良好的有效性与鲁棒性,能够确保查询与最相关的上下文进行准确匹配。
消融实验(Ablation Study)
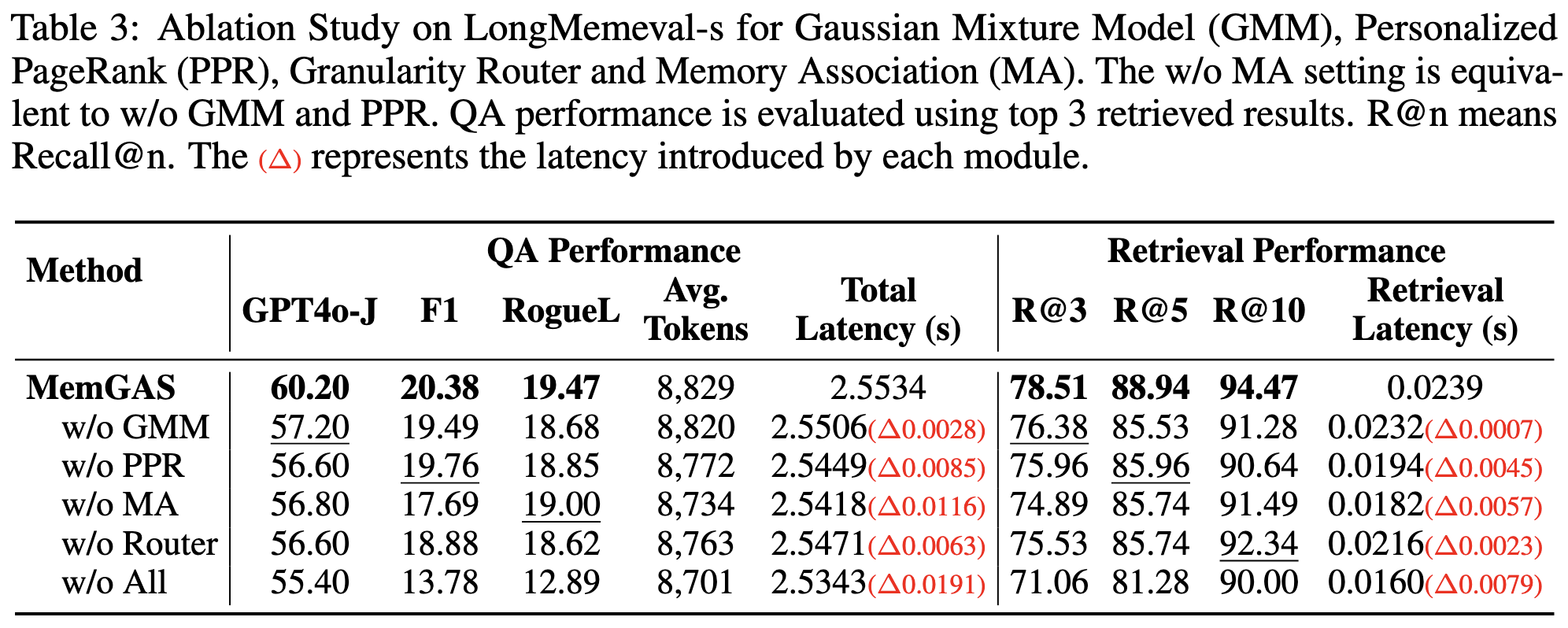
表3中的消融实验结果表明,各个组件在提升问答(QA)和检索性能方面都具有重要作用。无论是单独移除高斯混合模型(GMM)、个性化PageRank(PPR)、记忆关联(MA)还是路由器(Router),都会导致性能持续下降,从而验证了这些模块的关键贡献。尤其是在移除所有组件的情况下,性能下降最为显著:F1 分数从 20.38 降至 13.78,Recall@3 从 78.51 降至 71.06,这进一步说明各模块在整体性能提升中的不可或缺性。
此外,这些模块引入的额外延迟非常有限,其中问答任务的最大延迟增加仅为 0.0191 秒,检索任务为 0.0079 秒。我们还发现,LLM 的 API 调用占据了整体端到端延迟的 98% 以上,是系统响应时间的主要来源,而本文方法引入的额外开销在实际应用中是可以接受的。
综上所述,该架构在性能提升与计算效率之间实现了良好的平衡。